

一、简介
本文章是在学习《Python3入门机器学习 经典算法与应用 轻松入行人工智能(完整版) - 499元》课程的时候,做的一些笔记,方便回顾。
二、概念
三、sklearn工具
本文章是机器学习的入门教程,主要使用了sklearn库,该章节是为了更快地回顾记忆sklearn中的各个工具,以及使用方法
sklearn中文文档网页-【布客】sklearn 中文翻译
3.1 sklearn.linear_model 模块
3.1.1 sklearn.linear_model.LinearRegressor (线性回归)
3.1.1 sklearn.linear_model.SGDRegressor (梯度下降法的线性回归)
3.1.1 sklearn.linear_model.Ridge (岭回归)
模型正则化通过限制模型参数的大小来防止过拟合,提高模型的泛化能力。岭回归通过在损失函数中加入与模型参数平方和的阿尔法值项,对模型参数进行约束。阿尔法值是超参数,需要在预测准确度和参数大小之间取得平衡。
3.1.2 sklearn.linear_model.Lasso (LASSO回归)
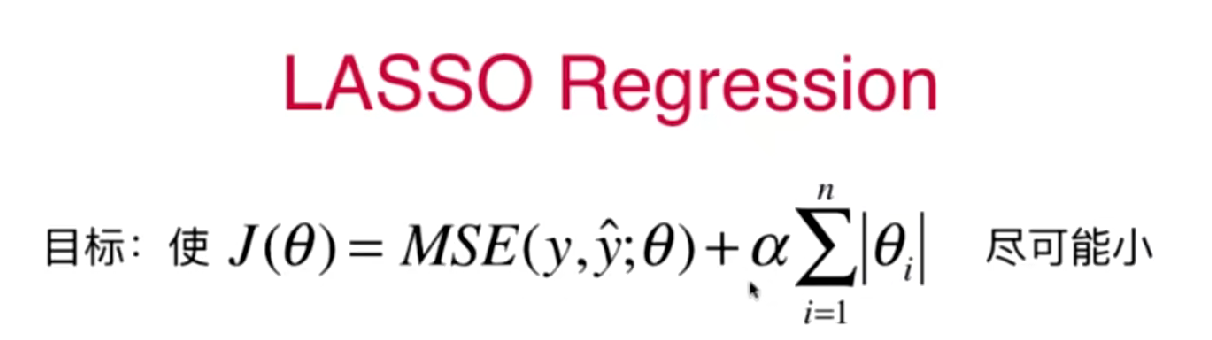
3.1.3 sklearn.linear_model.LogisticRegression (逻辑回归)
3.2 sklearn.model_selection 模块
3.2.1 sklearn.model_selection.train_test_split (数据集拆分:训练数据集、测试数据集)
3.2.2 sklearn.model_selection.GridSearchCV (网格搜索)
3.3 sklearn.metrics 模块(模型评估指标相关)
3.3.1 sklearn.metrics.precision_recall_curve (准确率召回率曲线)
3.3.2 sklearn.metrics.roc_curve (ROC曲线)
3.3.3 sklearn.metrics.roc_auc_score (AUC指标,也就是ROC曲线下包围的面积)
3.3.4 sklearn.metrics.accuracy_score (准确度分值,等价于分类模型的score函数)
3.3.5 from sklearn.metrics import mean_squared_error (均方误差MSE)
3.3.6 from sklearn.metrics import mean_absolute_error (平均绝对误差)
3.3.7 from skleran.metrics import r2_score (R2决定系数)
3.4 sklearn.preprocessing 模块
3.4.1 sklearn.preprocessing.StandardScaler (数据归一化)
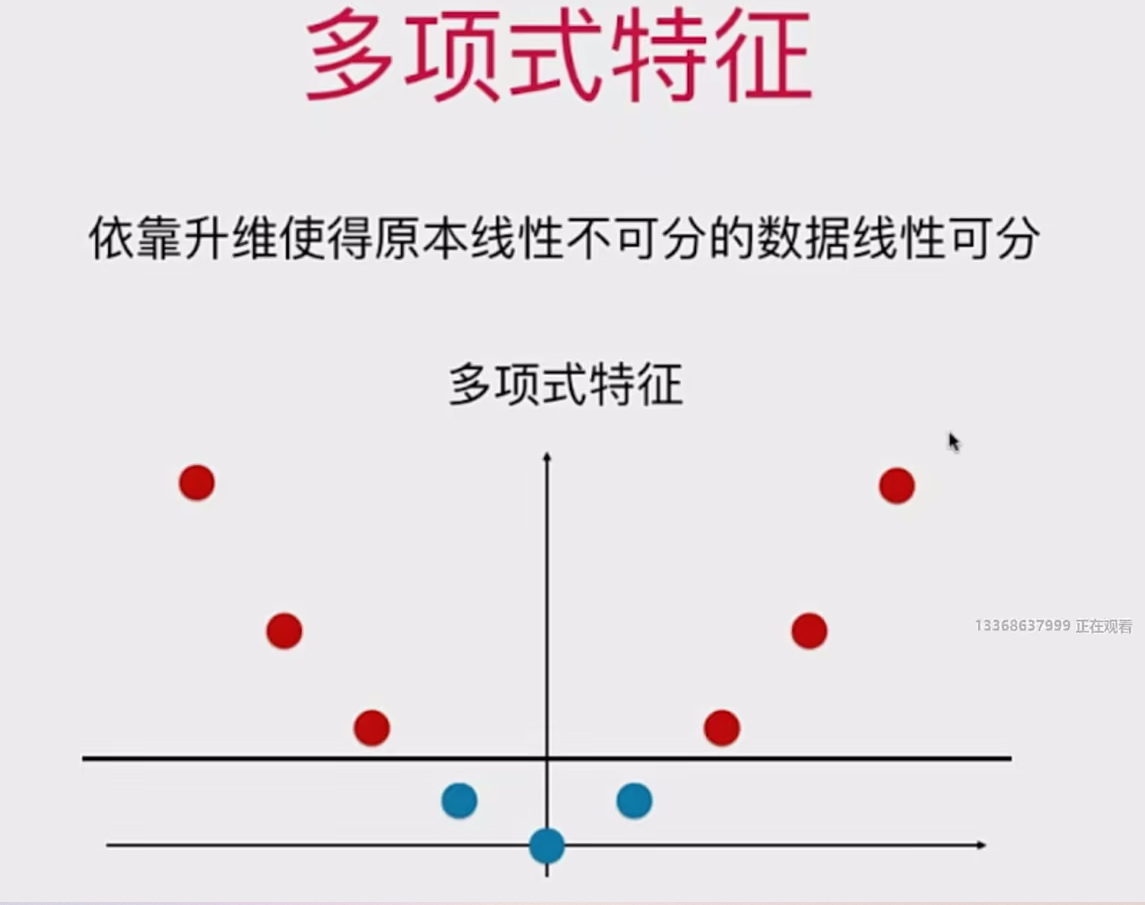
3.4.2 sklearn.preprocessing.PolynomialFeatures (多项式特征)
3.5 sklearn.svm 模块
3.5.1 sklearn.svm.LinearSVC (线性SVM)
3.5.2 sklearn.svm.SVC (天然支持非线性SVM,无需通过PolynomialFeatures,SVC(kernel="poly",degree=degree,C=C))
3.6 sklearn.pipeline (管道)
3.6.1 sklearn.pipeline.Pipeline (管道)
3.7 sklearn.tree (决策树)
3.7.1 sklearn.tree.DecisionTreeClassifier (决策树分类)
3.7.2 sklearn.tree.plot_tree (可视化决策树)
3.8 skleran.ensemble(集成学习/随机森林)
3.8.1 from sklearn.ensemble import VotingClassifier (集成学习)
3.8.2 from sklearn.ensemble import BaggingClassifier (集成学习Bagging)
3.8.3 from sklearn.ensemble import RandomForestClassifier (随机森林)
3.8.4 from sklearn.ensemble import ExtraTreesClassifier (随机森林ExtraTrees)
3.8.5 from sklearn.ensemble import BaggingRegressor (集成学习Bagging解决回归问题)
3.8.6 from sklearn.ensemble import RandomForestRegressor (随机森林解决回归)
3.8.7 from sklearn.ensemble import ExtraTreesRegressor (随机森林ExtraTrees解决回归)
3.8.8 from sklearn.ensemble import AdaBoostClassifier (AdaBoost 集成学习的另一种思路,强化)
3.8.9 sklearn.ensemble import GradientBoostingClassifier (GradientBoost)
3.8.8 from sklearn.ensemble import AdaBoostRegressor (AdaBoost解决回归)
3.8.9 from sklearn.ensemble import GradientBoostingRegressor (GradientBoosting解决回归)
3.9 sklearn.multiclass (多分类,解决多分类问题)
3.9.1 from sklearn.multiclass import OneVsOneClassifier (OvO多分类)
3.9.2 from sklearn.multiclass import OneVsRestClassifier (OvR多分类)
四、课程具体章节
第1章 欢迎来到Python3玩转机器学习
1-1 什么是机器学习
1-2课程涵盖的内容和理念
1-3课程所使用的技术栈
第2章 机器学习基础
2-1 机器学习的数据
2-2 机器学习的主要任务
2-3 监督学习、非监督学习...
2-4 批量、在线学习、参数、非参数学习
2-5 哲学思考
2-6 课程使用环境搭建
第3章 Jupyter Notebook ,numpy
3-1 Jupyter Notebook基础
3-2Jupter Notebook 中的魔法命令
3-3 Numpy 数据基础
3-4 创建Numpy 数据和矩阵
3-5 Numpy数组和矩阵的基本操作
3-6 Numpy 数据和矩阵的合并与分割
3-7 Numpy中的矩阵运算
3-8 Numpy 中的聚合运算
3-9 Numpy中的arg运算
3-10 Numpy中的比较和Fancy lindexing
3-11 Matplotlib数据可视化基础
3-12 数据加载和简单的数据搜索
第4章 最基础的分类算法
4-1 K近邻算法
4-2 scikit-learn机器学习算法封装
4-3 训练数据集
4-4 分类准确度
4-5 超参数
4-6 网络搜索与K邻近算法中更多超参数
4-7 数据归一化
4-8 Scikit-learn中的Scaler
4-9 更多有关K近邻算法的思考
第5章 线性回归法
5-1 简单线性回归
5-2 最小乘法
5-3 简单线性回归的实现
5-4 衡量线性回归的指标
5-5 R Squared
5-6 最好的 衡量线性回归法的指标
5-7多元线性回归和正规方程解
5-8 实现多元线性回归
5-9 使用Scilit-learn解决回归问题
5-10 线性回归的可解释性
第6章 梯度下降法
6-1 什么是梯度下降法
6-2线性回归中的梯度下降法
6-3实现线性回归中的梯度下降法
6-4 实现线性回归中的梯度下降法
6-5 梯度下降法 的向量化
6-6 随机梯度下降法
6-7 scikit-learn中的梯度下降法
6-8有关梯度下降法的更多深入讨论
6-9 有关梯度下降法的更多讨论
第7章 PCA与梯度上升法
7-1 什么是PCA
7-2 求数据的主成分PCA问题
7-3 求数据的主成分
7-4 高维数据映射为低维数据
7-5 高纬数据映射为低纬数据
7-6 scikit-learn中的PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=2) #n_components主成分个数
pca.fit(X)
pca.components_ #获取主成分结果参数
#使用transform方法进行降维
X_reduction = pca.transform(X)
#反向操作:
X_restore= pca.inverse_transform(X_reduction)
pca.explained_variance_ratio_ #获取各成份/维度的方差值n_components参数是设置保留的主成分的个数,这个值影响了pca对最终结果的误差,如果太小就丢失太多数据,太大的话意义就不大,理论上可以使用网格搜索的方式找到最合适的值,但sklearn中的PCA为我们提供了一个explained_variance_ratio_参数,可以获取这些主成分的方差值,PCA算法就是要找到使方差最大的那组数据,通过这个参数,就可以知道大概保留多少个主成份,对于高纬度的数据集,
plt.plot([i for i in range(X_train.shape[1])],[np.sum(pca.explained_variance_ratio_[:i+1])] for i in range(X_train.shape[1]))
plt.show()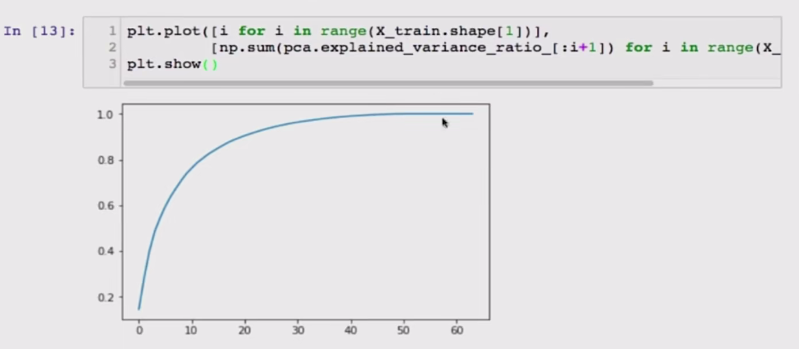
而根据需要的方差量来找到对应的主成分个数的这个问题,就可以通过这个图来找到。sklearn中已经封装好了这个功能,可以直接传入一个0-1的浮点数给n_components参数,sklearn会自动的找大对应的主成分个数
pca = PCA(0.95)
pca.fit(X_train)
pca.n_components_ #得到主成分个数(特征个数),就可以满足95%的方差误差,也就是只丢失5%的信息7-7 试手MNIST数据集
7-8 使用PCA对数据进行降噪
7-9 人脸识别与特征脸
所谓的特征脸,其实就是把pca.components_当作是特征来看,然后同样地绘制出图片,可以反馈出人脸的特征,最靠前的特征最重要最核心,后面的特征则是丰富。特征脸是PCA在人脸识别领域专门的一个应用
from sklearn.datasets import fetch_lfw_people #人脸数据
faces = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
#绘制人脸
random_indexes = np.random.permutation(len(faces.data))
X = faces.data[random_indexes]
example_faces = X[:36,:]
example_faces.shape
def plot_faces(faces):
fig,axes=plt.subplots(6,6,figsize=(10,10),subplot_kw={"xticks":[],"yticks":[]},gridspec_kw=dict(hspace=0.1,wspace=0.1))
for i ,ax in enumerate(axes.flat):
ax.imshow(faces[i].reshape(50,37),cmap='bone')
plot_faces(example_faces)
#绘制特征脸
from sklearn.decomposition import PCA
pca = PCA(svd_solver = 'randomized')
pca.fit(X)
plot_faces(pca.components_[:36,:]) #把pca.components_当作是特征来看第8章 多项式回归与模型泛化
8-1 什么是多项式回归
8-2 scikit-learn 中的多项式回归
8-3 过拟合与欠拟合
8-4 为什么要训练数据集与测试数 据集
8-5 学习曲线
8-6 验证数据集与交叉验证
8-7 偏差方差平衡
8-8 模型泛化与岭回归
8-9 LASSO
8-10 L1,L2弹性网络
第9章 逻辑回归
9-1 什么是逻辑回归
逻辑回归的基本概念
逻辑回归解决的是分类问题,而不是回归问题。
逻辑回归通过将样本特征与样本发生的概率联系起来进行预测。
逻辑回归预测的是样本发生的概率,是一个介于0到1之间的值。
逻辑回归的适用场景
逻辑回归适用于解决二分类问题,不适用于多分类问题。
逻辑回归的概率计算方法
逻辑回归通过线性回归的方式找到一组θ参数,与特征x相乘得到一个中间值。
将中间值通过sigmoid函数转换成一个介于0到1之间的概率值。
sigmoid函数的表达式为1/(1+e^(-θx)),其值域在0到1之间,适合表示概率。


9-2 逻辑回归的损失函数
线性回归与逻辑回归的损失函数
线性回归使用均方误差(MSE)作为损失函数,通过最小化损失函数求解θ。
逻辑回归使用交叉熵损失函数,形式较为复杂,但整体方向与线性回归相似。
逻辑回归的总损失函数
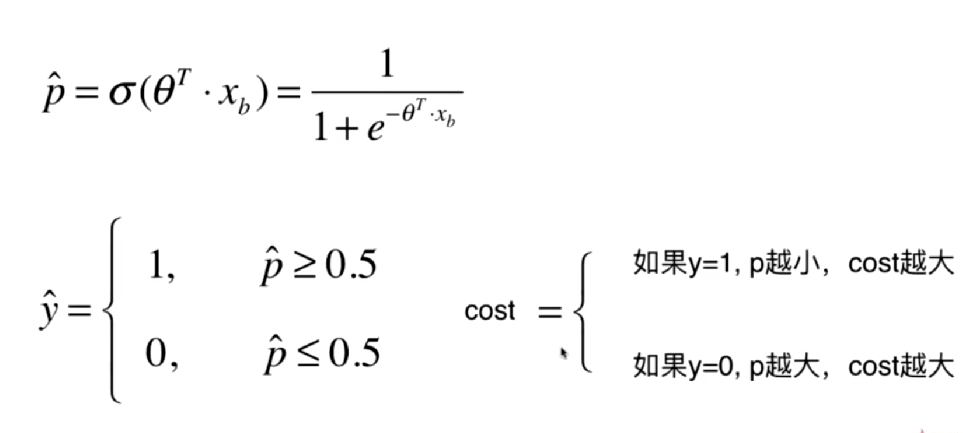


逻辑回归的损失函数较为复杂,没有数学解析解,需使用梯度下降法求解。
梯度下降法通过迭代调整θ值,使损失函数最小化。
逻辑回归的损失函数是凸函数,存在唯一全局最优解,无需担心局部最优解问题。
9-3 逻辑回归损失函数的梯度
推导过程省略。。。
损失函数总体的导数
1.将损失函数前半部分和后半部分的导数相加,得到总体导数。


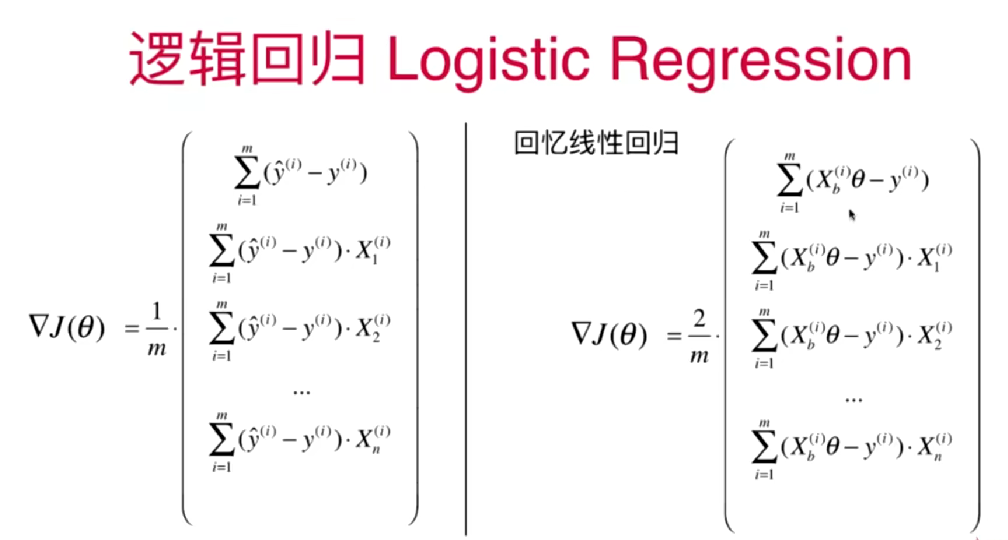
梯度的向量化表示

9-4 实现逻辑回归算法
def _sigmoid(self, t):
return 1. / (1. + np.exp(-t))
def fit(self, X_train, y_train, eta=0.01, n_iters=1e4):
"""根据训练数据集X_train, y_train, 使用梯度下降法训练Logistic Regression模型"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
def J(theta, X_b, y):
y_hat = self._sigmoid(X_b.dot(theta))
try:
return - np.sum(y*np.log(y_hat) + (1-y)*np.log(1-y_hat)) / len(y)
except:
return float('inf')
def dJ(theta, X_b, y):
return X_b.T.dot(self._sigmoid(X_b.dot(theta)) - y) / len(y)
def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e4, epsilon=1e-8):
theta = initial_theta
cur_iter = 0
while cur_iter < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
cur_iter += 1
return theta
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.zeros(X_b.shape[1])
self._theta = gradient_descent(X_b, y_train, initial_theta, eta, n_iters)
self.intercept_ = self._theta[0]
self.coef_ = self._theta[1:]
return self9-5 决策边界
决策边界的概念
决策边界是分类问题中的一个重要概念,它的本质是使用足够密的点来判断分类并绘制出决策边界。
逻辑回归算法的决策边界是直线(不使用多项式特征的情况下)
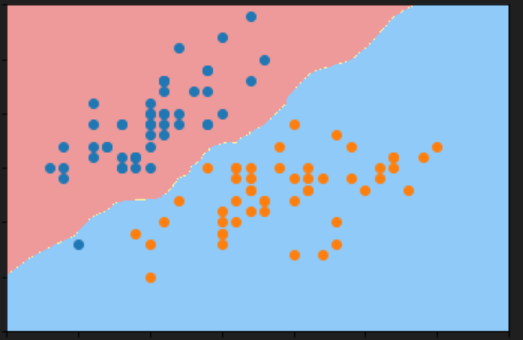
代码实现
def plot_decision_boundary(model, axis):
#生成密集的网格点集
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
#对密集的网格点集中的每个点进行预测,这个预测值相当于作为z值,根据z值来赋予不同的颜色
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
#这里引入了ListedColormap,列表颜色映射,用于分配不同的颜色
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
plot_decision_boundary(log_reg, axis=[4, 7.5, 1.5, 4.5])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
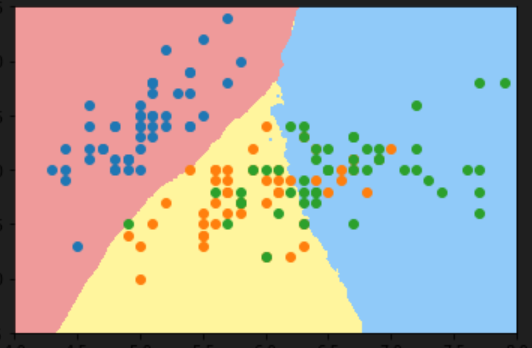
plt.show()9-6 在逻辑回归中使用多项式特征
逻辑回归与二分类问题
逻辑回归的本质是在特征平面上找到一条直线来分割两个分类。
逻辑回归只能解决二分类问题,因为直线只能将特征平面分成两部分。
非线性分布的分类问题
对于非线性分布的样本点,无法使用直线进行分割。
需要使用更复杂的决策边界,如圆形,来进行分类。
多项式回归与逻辑回归
通过引入多项式特征,线性回归可以学习到非线性的决策边界。
同理,逻辑回归也可以通过添加多项式特征来处理非线性数据。
代码
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
def PolynomialLogisticRegression(degree):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression())
])模型正则化与过拟合
模型正则化是解决过拟合的通用方法。
减少多项式特征的阶数可以简化模型,防止过拟合。
逻辑回归中,增加模型正则化可以提高泛化能力。

在sklearn的LogisticRegression中,带有一个参数C,这个C就是模型正则化
9-7 scikt-learn中的逻辑回归
scikit-learn中的逻辑回归正则化
scikit-learn中的逻辑回归实现了这种正则化方式,通过调整C和penalty参数来控制正则化的强度和类型。
默认情况下,逻辑回归使用L2正则化,C的值为1。
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
def PolynomialLogisticRegression(degree, C, penalty='l2'):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression(C=C, penalty=penalty))
])
poly_log_reg4 = PolynomialLogisticRegression(degree=20, C=0.1, penalty='l1')
poly_log_reg4.fit(X_train, y_train)9-8 OvR与OvO
逻辑回归与多分类问题
逻辑回归是一种常用的机器学习算法,主要用于解决二分类问题。
通过一些改造,逻辑回归也可以用于解决多分类问题。
这种改造方式不仅适用于逻辑回归,还适用于许多其他的二分类算法。
OvR与OvO方法
OvR(one versus rest)方法:将多分类问题分解为多个二分类问题。
OvO(one versus one)方法:每次比较两个类别,通过比较结果进行投票。
OvR方法简单,但计算复杂度较高;OvO方法准确,但计算复杂度更高。
在sklearn中的LogisticRegression自动为我们添加了对多分类的支持,其有一个multi_class的参数,默认值是ovr。如果需要使用ovo模式,则需要将multi_class="multinomial",而不是传入“ovo”
第10章 评价分类结果
10-1 准确度的陷阱和混淆矩阵
10-2 准确率和召回率
10-3 现实混淆矩阵
10-4 F1 Score
10-5 准确率和召回率的平衡
10-6 准确率召回率曲线
主要讲述了如何通过绘制precision-recall曲线来评估机器学习模型的性能。首先介绍了precision和recall的概念,以及它们在评估模型中的重要性。然后通过绘制precision-recall曲线,展示了随着阈值的变化,precision和recall的变化趋势。此外还介绍了如何通过ROC曲线来评估模型性能,并解释了ROC曲线和precision-recall曲线的区别和联系。最后通过比较不同模型的precision-recall曲线,展示了如何判断模型的优劣。
决策分数与阈值调整
决策分数:分类算法对每个样本的决策分数,逻辑回归中默认以零为判断标准。
阈值调整:通过调整阈值,精准率和召回率会发生变化,两者互相制约、平衡。
可视化精准率与召回率曲线
决策分数范围:通过numpy的min和max函数找到决策分数的最小值和最大值。
阈值数组:使用numpy的arrange函数生成阈值数组,步长为0.01。
绘制曲线:针对每个阈值,绘制出精准率和召回率。
代码
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train,y_train)
decision_scores = log_reg.decision_function(X_test)
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_test, decision_scores) #计算准确率集合、召回率集合、thresholds阈值集合
#准确率召回率阈值曲线
plt.plot(thresholds, precisions[:-1])
plt.plot(thresholds, recalls[:-1])
plt.show()
#Precision-Recall 准确率召回率曲线
plt.plot(precisions, recalls)
plt.show()准确率召回率阈值曲线
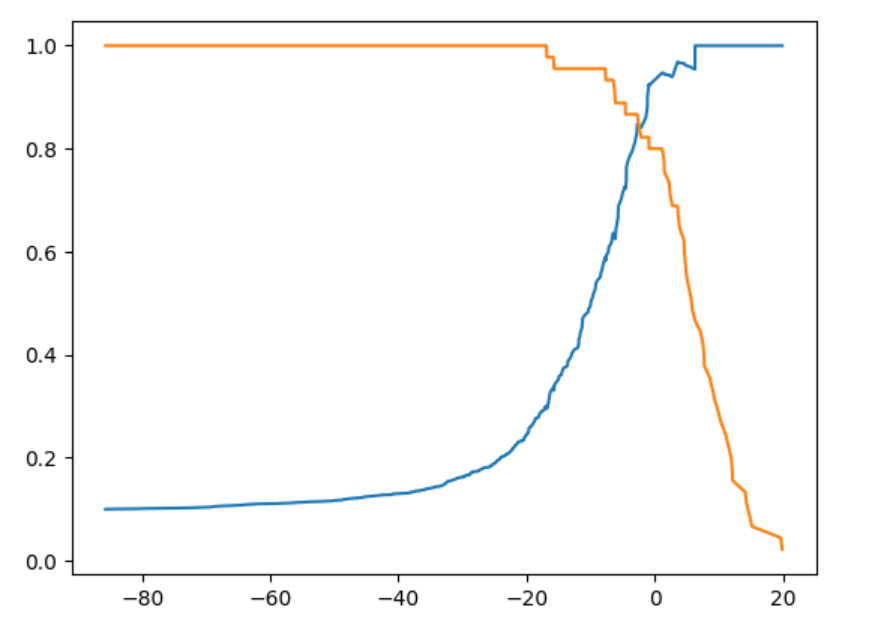
Precision-Recall 准确率召回率曲线
使用准确率召回率曲线,可以快速找到目标准确率或召回率所需要的决策分数阈值范围。
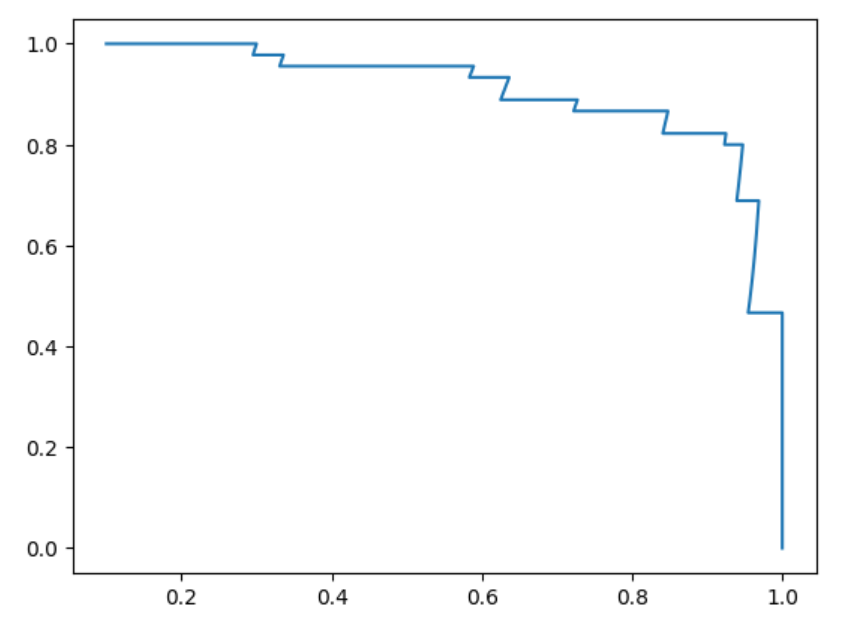
10-7 ROC曲线
ROC曲线(Receiver Operating Characteristic Curve)是描述TPR和FPR之间关系的曲线,常用于评估二分类模型的性能。
TPR和FPR的定义
TPR(True Positive Rate)是真正例率,与召回率(Recall)意思相同,表示预测为正例且预测正确的样本占真实正例的比例。
FPR(False Positive Rate)是假正例率,表示预测为正例但预测错误的样本占真实负例的比例。
当阈值增大时,TPR降低,FPR也降低;当阈值减小时,TPR增高,FPR也增高。
ROC曲线下面积的意义
ROC曲线下面积(AUC)越大,表示分类算法的性能越好。
AUC值越大,说明模型在低FPR下具有较高的TPR,即模型对正例的识别能力越强。
AUC的应用场景(AUC就是ROC曲线的下的面积)
AUC主要用于比较两个模型或算法的优劣。
在选择模型时,应选择AUC值更大的模型。
from sklearn.metrics import roc_curve
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train,y_train)
decision_scores = log_reg.decision_function(X_test)
fprs,tprs,threshholds = roc_curve(y_test,decision_scores )
plt.plot(fprs,tprs)
plt.show()from sklearn.metrics import roc_auc_score
roc_auc_score(y_test,decision_scores) #AUC就是ROC曲线的下的面积
10-8 多分类问题中的混淆矩阵
该视频主要讲述了如何通过绘制误差矩阵来分析多分类问题中分类算法的错误分布,以及如何评价分类算法的指标。
混淆矩阵天生支持多分类问题,而精确率、召回率等可以通过修改average参数为“micro”来支持多分类问题(默认不支持会报错)
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,y_predict) #混淆矩阵天生支持多分类问题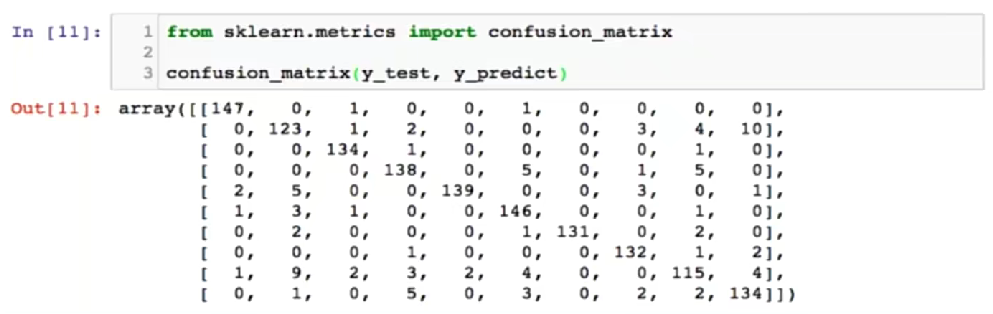
将混淆矩阵绘制出来,使用plt.matshow()
cfm = confusion_matrix(y_test,y_predict)
plt.matshow(cfm,cmap=plt.cm.gray) #cmap是设置映射颜色,gray代表映射灰度值
plt.shot()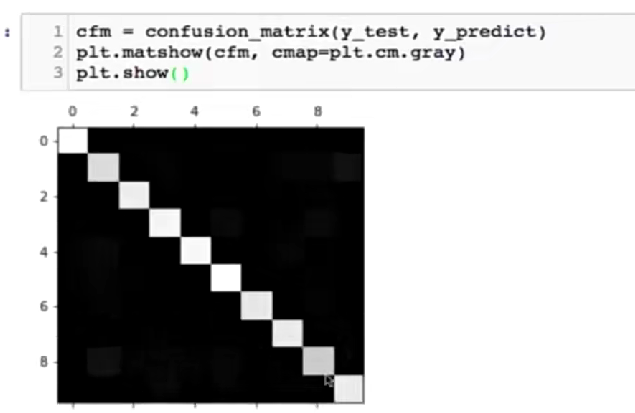
关注预测错误的地方(对角线是正确的,所以去掉对角线后,再去进行显示,)
错误矩阵的生成和应用
1.错误矩阵定义:将混淆矩阵的每个元素除以该行的总和,得到错误百分比。
2.错误矩阵应用:通过错误矩阵,可以进一步分析模型的具体错误,并针对这些错误进行算法优化。
row_sums = np.sum(cfm,axis=1)
err_matrix = cfm/row_sum #得到百分比
np.fill_diagonal(err_matrix,0) #将对角线设置为0
plt.matshow(err_matrix ,cmap=plt.cm.gray) #cmap是设置映射颜色,gray代表映射灰度值
plt.shot()
第11章 支撑向量机SVM
11-1 什么是SVM
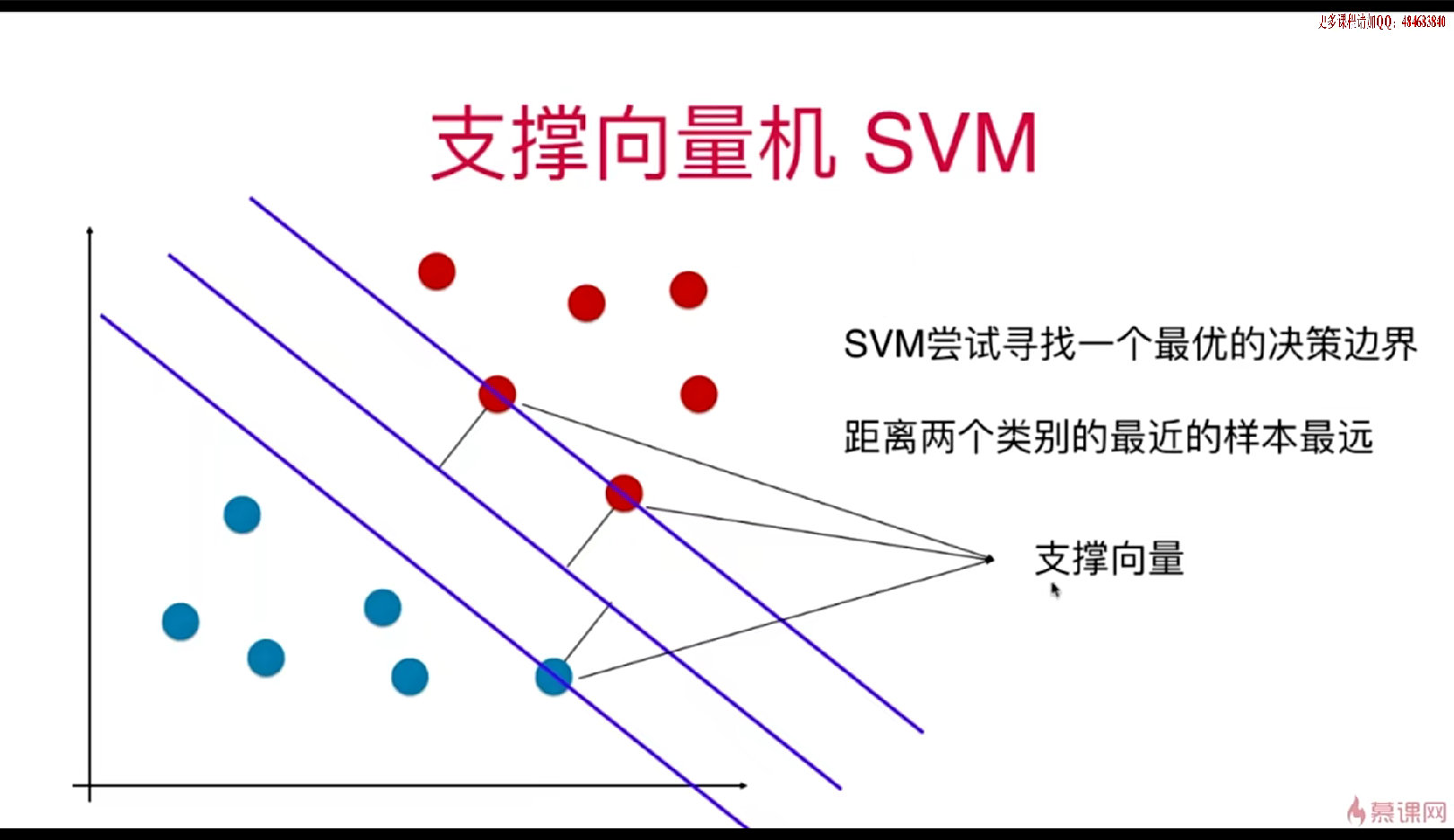
支撑向量机介绍
支撑向量机(SVM)是一种经典的机器学习算法,主要用于分类和回归问题。
SVM的基本思想是找到一个决策边界,使得该边界到两类数据的距离最远。
SVM既可以解决分类问题,也可以解决回归问题。
SVM的基本思想
SVM通过找到一个最优的决策边界来最大化分类间隔,从而提高泛化能力。
决策边界应该离两类数据都尽可能远,以减少误分类的可能性。
支撑向量定义了决策边界的区域,并决定了margin的大小。
硬边际支撑向量机(Hard-Margin SVM)
硬边际SVM适用于线性可分的数据,可以找到一个完美的决策边界。
通过最大化margin来求解最优的决策边界。
margin的大小是两倍的离决策边界最近的点的距离。
软边际支撑向量机(Soft-Margin SVM)
软边际SVM适用于线性不可分的数据,通过引入松弛变量来允许一些误分类。
在最大化margin的同时,也考虑了误分类的程度。
软边际SVM在硬边际SVM的基础上进行了改进,以处理更复杂的数据集。
11-2 svm背后的最优化问题

svm算法的最优化问题
svm算法的最优化问题为目标函数1/2w²模的最小化。
约束条件为所有数据点满足yi×(wxi+b)≥1的不等式关系。
有条件的最优化问题,比全局最优化问题的推导难很多,所以没有推导

11-3 Soft Margin SVM
该视频主要讲述了soft margins VM的概念及其在hard margins VM基础上的改进。soft margins VM允许决策边界有一定的容错能力,以提高泛化能力。与hard margins VM相比,soft margins VM放宽了条件,允许数据点在margin区域外有一定的宽松量。此外,视频还介绍了正则化的概念,指出正则化本质是一个约束条件,用于防止模型过拟合。通过学习soft margins VM和正则化,可以更深刻地理解这些概念在机器学习中的应用。

11-4 Scikit-learn 中的SVM
数据标准化处理
在使用SVM之前,对数据进行标准化处理是非常重要的。
标准化处理的目标是使不同维度上的特征具有相同的尺度。
如果不进行标准化,特征尺度差异过大可能会影响SVM的性能。
from sklearn.svm import LinearSVC #线性SVM
svc = LinearSVC(C=1e9)
svc.fit(X_standard,y)
在sklearn中的svm算法是做好了解决多分类问题了,并且可以通过修改multi_class来修改成ovr或ovo这两种多分类方式;还以修改penalty参数为“l1”或“l2”来修改成L1正则或L2正则
11-5 SVM中使用多项式特征和核函数
使用以前的多项式特征:
from sklearn.preprocessing import PolynomialFeatures,StandardScaler
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
def PolynomialSVC(degree,C=1.0):
return Pipeline([
("poly",PolynomialFeatures(degree=degree)),
("std_scaler",StandardScaler()),
('linearSVC',LinearSVC(C = C))
])
SVM有一种特殊的方式,可以直接使用多项式特征,而不需要通过PolynomialFeatures¶
使用多项式核函数的SVM(使用SVC这个类,并且将kernel="poly",同样可以达到多项式这样的效果)
from sklearn.svm import SVC
def PolynomialKernelSVC(degree,C=1.0):
return Pipeline([
("std_scaler",StandardScaler()),
("kernelSVC",SVC(kernel="poly",degree=degree,C=C))
])
11-6 什么是核函数
该视频主要讲述了核函数在支持向量机(SVM)中的重要应用。核函数通过将原始数据映射到更高维度的特征空间,降低计算的复杂度,提高分类的准确率
核函数的基本概念
核函数(Kernel Function)在SVM算法中扮演重要角色。
核函数的英文是kernel function。
核函数的定义:在SVM中,核函数是一种替换原始样本点内积运算的函数。

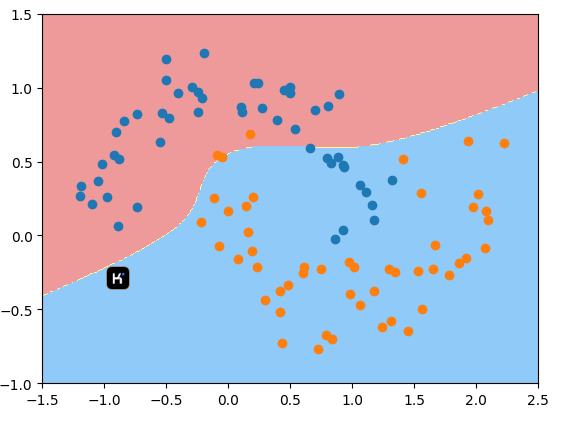
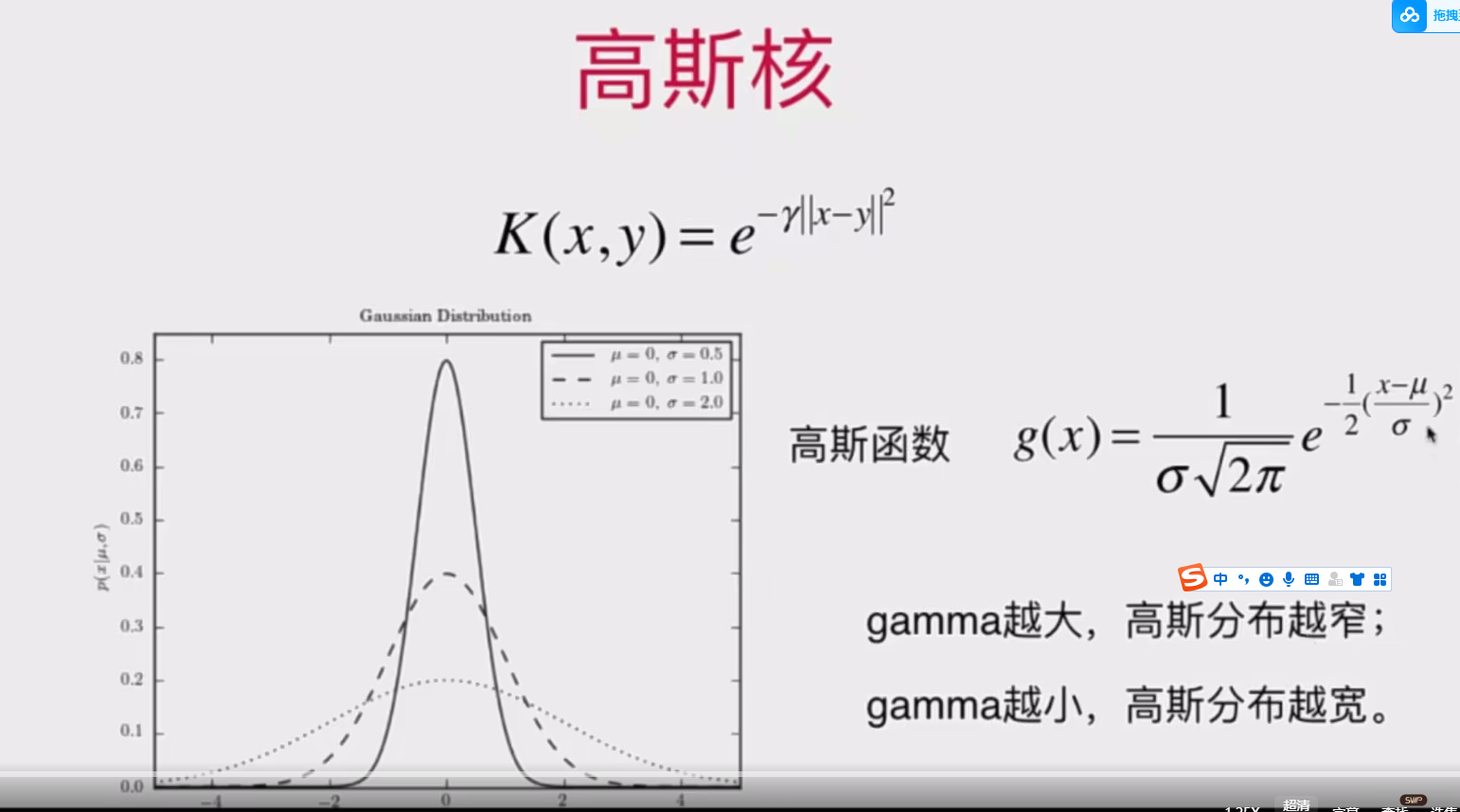
11-7 RBF核函数(高斯核函数,SVM算法使用最多的一种核函数)
高斯核函数,也叫RBF核函数,Radial Basis Function Kernel ,中文也叫径向基函数

高斯核的本质:是将一个样本点映射到一个无穷维的特征空间
多项式特征的本质:
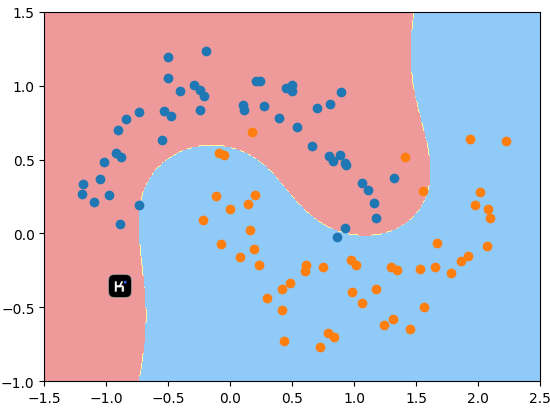
11-8 RBF核函数中的gamma
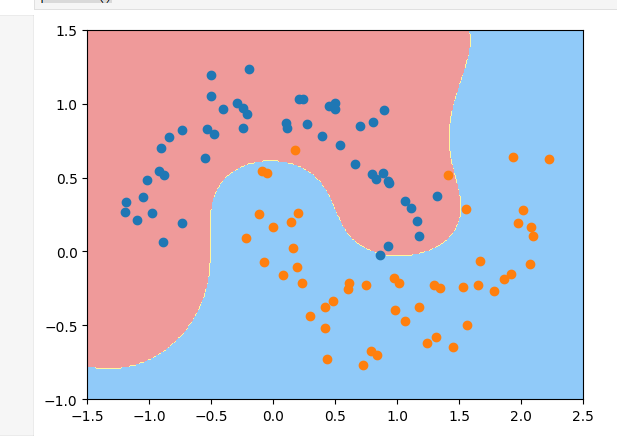
gamma越大,高斯分布越窄,模型越倾向于过拟合
gamma越小,高斯分布约宽,模型越倾向于欠拟合
代码
from sklearn.svm import SVC
def RBFKernelSVC(gamma = 1.0):
return Pipeline([
("std_scaler",StandardScaler()),
("kernelSVC",SVC(kernel="rbf",gamma=gamma))
])
#创建模型并训练
svc = RBFKernelSVC(gamma=1.0)
svc.fit(X,y)
#显示一下决策边界
plot_decision_boundary(svc,axis =[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()11-9 SVM思想解决回归问题
第12章 决策树
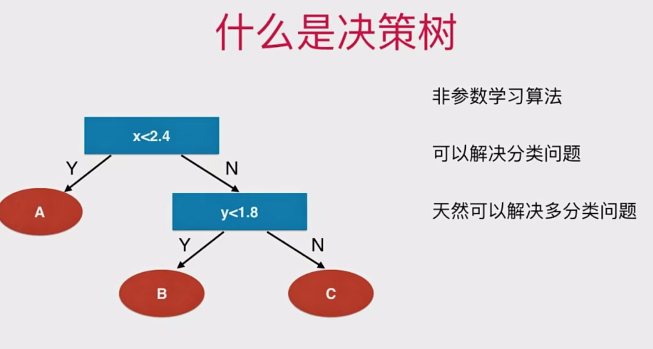
12-1 什么是决策树
决策树的基本概念
决策树是一种重要的机器学习算法,广泛应用于分类和回归问题。
决策树的工作流程类似于生活中的决策过程,通过一系列条件判断进行数据分类。
决策树的树形结构包括节点、根节点、叶子节点和树的深度。
决策树处理数值特征
决策树不仅可以处理离散特征,还可以处理连续数值特征。
在每个节点上,决策树选择一个维度(特征)和一个阈值进行判断,将数据分成两个分支。
决策树通过选择合适的维度和阈值来最大化分类效果。
决策树的特点和适用场景
决策树是一种非参数学习算法,适用于分类和回归问题。
决策树可以天然处理多分类问题,而不需要像逻辑回归或SVM那样通过OVR或OVO手段解决。
决策树也适用于回归问题,通过计算叶子节点中样本数据的平均值进行预测。
决策树算法具有较好的可解释性,可以清晰地解释样本数据被分成某一类的依据。
代码:
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(max_depth=2,criterion="entropy") #entropy是熵的意思
dt_clf.fit(X,y)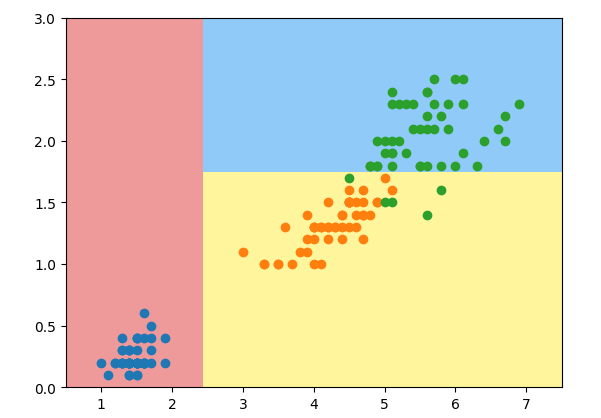
其他:
在sklearn中有专门针对决策树的可视化工具,plot_tree
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# 加载数据
iris = load_iris()
X, y = iris.data, iris.target
# 训练决策树(使用基尼系数)
# clf = DecisionTreeClassifier(max_depth=2, criterion='gini')
clf = DecisionTreeClassifier(max_depth=2, criterion='entropy')
clf.fit(X, y)
# 可视化决策树
plt.figure(figsize=(12,8))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()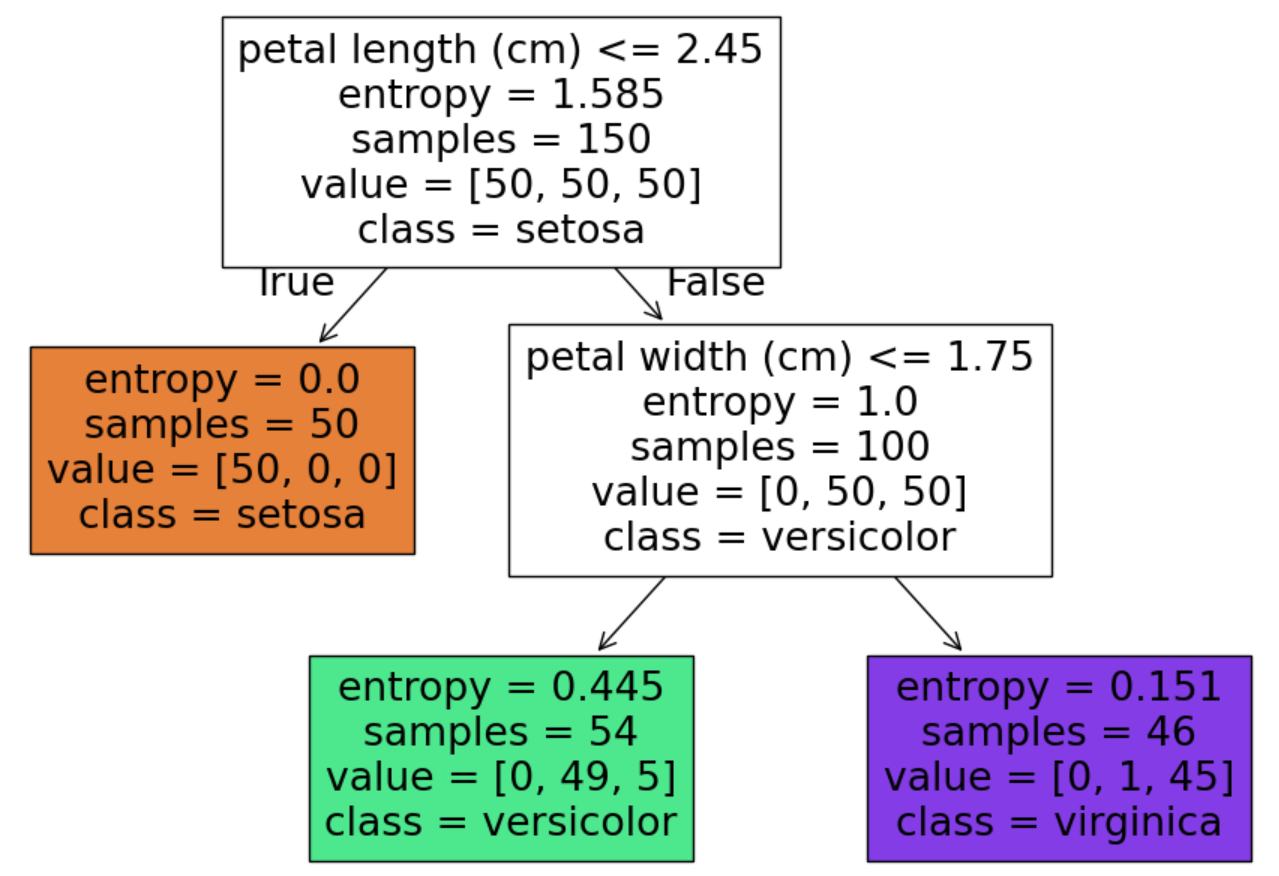
12-2 信息熵
信息熵概念
信息熵是信息论的基础概念,表示随机变量的不确定度。
信息熵越大,数据越不确定;信息熵越小,数据越确定。
信息熵的概念可以从物理热力学中粒子无规则运动的角度理解。
12-3 使用信息熵寻找最优划分
12-4 基尼系数
其实跟信息熵是一样的代码,只是criterion参数设置成gini
大多数情况西信息熵和基尼系数这两种得到的结果是相同的
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(max_depth=2,criterion='gini')
dt_clf.fit(X,y)
12-5 CART与决策树中的超参数
决策树还有一个名字,称为CART (Classification And Regression Tree),
sklearn中的决策树实现是使用CART来实现的,除此之外还有ID3,C4.5,C5.0等方法实现
决策树容易产生过拟合,解决方法是“剪枝”处理,在sklearn中的DecisionTreeClassifier里面,有很多的参数

12-6 决策树解决回归问题
决策树的回归问题和分类问题,调用方式基本是一模一样的,只是最后的结果是数值
from sklearn.tree import DecisionTreeRegressor
dt_reg = DecisionTreeRegressor()
dt_reg.fit(X_train,y_train)
决策树过拟合及其解决方案
决策树容易产生过拟合,特别是在训练数据集上表现完美但对测试数据集表现不佳。
通过调整决策树参数来防止过拟合,如设置最大深度、最小样本数等。
建议尝试调参以优化决策树在波士顿房价数据集上的表现。
12-7 决策树的局限性
决策树的最大局限性是决策边界横平竖直,不能很好地处理非线性关系。
决策树对个别数据点敏感,高度依赖于参数调整。
决策树的局限性在实际应用中需要通过集成学习等方法进行弥补。
ai总结经验
一、决策树基础概念
决策树是一种基于树状结构的**监督学习**算法,可用于分类和回归任务。其核心思想是通过一系列**规则判断**对数据进行分割,最终达到预测目标的目的。
核心组成元素:
1. 根节点:起始节点,包含全部样本
2. 内部节点:决策规则的分支节点
3. 叶节点:最终的预测结果
4. 分裂准则:如何选择最佳分割特征(如信息增益、基尼不纯度)
---
二、关键概念详解
1. 信息增益(ID3算法)
熵(Entropy):衡量数据集的混乱程度
\( H(S) = -\sum_{i=1}^c p_i \log_2 p_i \)
其中 \( p_i \) 是类别 \( i \) 在集合中的比例
信息增益 = 父节点熵 - 子节点加权平均熵
选择信息增益最大的特征进行分裂
2. 基尼不纯度(CART算法)
基尼系数:衡量数据不纯度
\( Gini(S) = 1 - \sum_{i=1}^c p_i^2 \)
选择基尼不纯度降低最多的特征分裂
三、实际案例演示
案例背景:鸢尾花分类
- 任务:根据花瓣/萼片长度宽度预测鸢尾花种类(Setosa/Versicolor/Virginica)
- 数据集:sklearn内置鸢尾花数据集(150个样本,4个特征)
代码实现步骤:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# 加载数据
iris = load_iris()
X, y = iris.data, iris.target
# 训练决策树(使用基尼系数)
clf = DecisionTreeClassifier(max_depth=2, criterion='gini')
clf.fit(X, y)
# 可视化决策树
plt.figure(figsize=(12,8))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()决策过程解析:
1. 根节点:基于花瓣宽度(petal width)进行首次分割
<=0.8 cm → 直接分类为Setosa
2. 第二层节点:
花瓣宽度 >0.8 cm时,进一步用花瓣长度(petal length)判断
<=1.75 cm → Versicolor
>1.75 cm → Virginica
四、决策树的特性
优点:
直观易懂(白盒模型)
无需特征标准化
可处理数值和类别数据
缺点:
容易过拟合(需通过剪枝控制)
对数据微小变化敏感
可能产生偏向于多值特征的树
---
五、进阶知识
1. 防止过拟合技术
预剪枝(Pre-pruning):
设置最大深度
max_depth设置叶节点最小样本数
min_samples_leaf
后剪枝(Post-pruning):通过代价复杂度剪枝
2. 重要参数解析
DecisionTreeClassifier(
criterion='gini', # 分裂标准(gini/entropy)
max_depth=None, # 树的最大深度
min_samples_split=2, # 节点分裂所需最小样本数
min_impurity_decrease=0.0 # 分裂需要的最小不纯度降低
)```
3. 决策树的扩展应用
回归树:使用方差作为分裂标准
集成方法:
随机森林(多棵树的组合)
梯度提升树(GBDT)
六、实际应用思考题
假设你要预测银行贷款违约风险:
哪些特征可能重要?(收入、信用评分、负债比等)
如何防止模型被个别异常值影响?
当特征间存在高度相关性时,决策树如何处理?
总结
决策树通过模仿人类决策过程,构建了可解释性极强的模型。理解其分裂准则和剪枝方法,是掌握后续随机森林、GBDT等集成方法的基础。建议通过`sklearn.tree.plot_tree`函数多观察不同参数下树结构的变化,这将加深你的理解。
第13章 集成学习和随机森林
13-1 集成学习
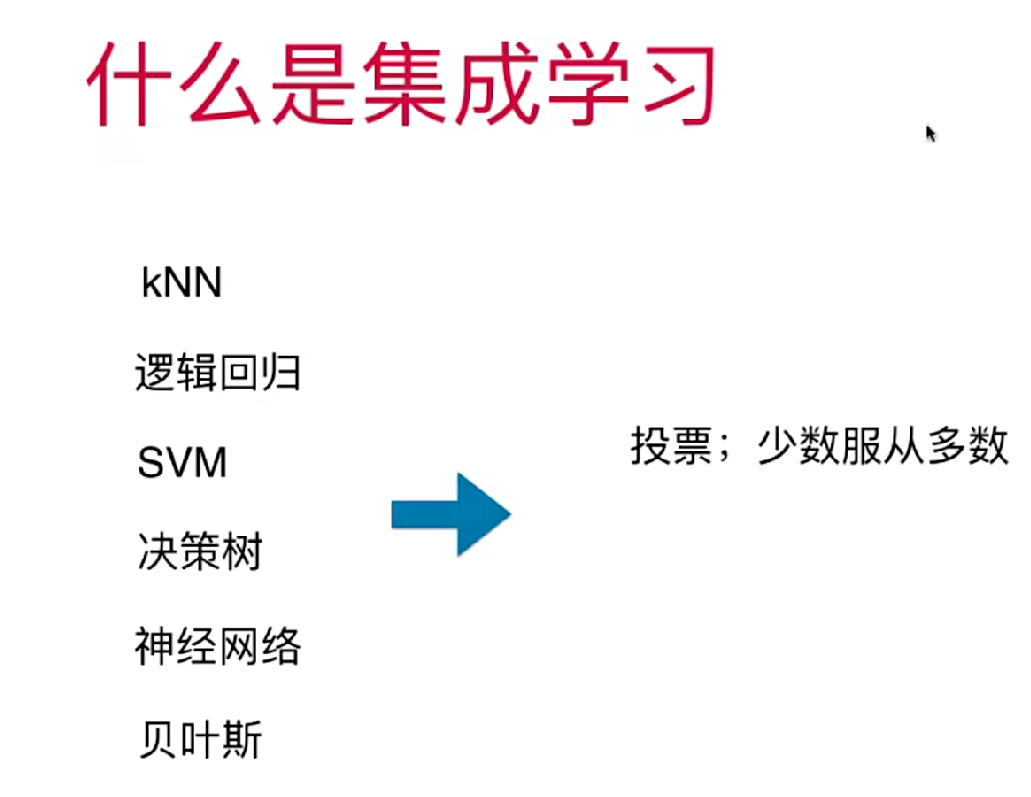
集成学习其实就是同时使用多种模型,进行投票,取票数多的那个作为结果。
sklearn提供一个一种Voting Classifier这样专门进行集成学习的分类器。Voting Classifier集成学习有两种:Hard和Soft
Hard Voting:少数服从多数,简单投票决定最终结果。
Soft Voting:考虑票数的权值,根据模型预测的概率进行加权投票。(更好)
以下是hard Voting 等权值的投票
from sklearn.ensemble import VotingClassifier
voting_clf = VotingClassifier(estimators=[
('log_clf',LogisticRegression()),
('svm_clf',SVC()),
('dt_clf',DecisionTreeClassifier()),
],voting='hard')13-2 Soft Voting 带权值的投票
把不同分类器分类的概率值作为权值

Soft Voting要求集合中的每一个模型都能估计概率,而在sklearn中,如果这个模型有predict_proba这个函数,就可以估计概率。
逻辑回归算法,支持。
kNN算法,支持。
决策树,支持
SVM算法,支持。SVC默认情况下是不支持的,但需要将probabillity参数设置为True,就可以估计概率
from sklearn.ensemble import VotingClassifier
voting_clf = VotingClassifier(estimators=[
('log_clf',LogisticRegression()),
('svm_clf',SVC(probability=True)),
('dt_clf',DecisionTreeClassifier(random_state=666)),
],voting='soft')
voting_clf.fit(X_train,y_train)
voting_clf.score(X_test,y_test)13-3 Bagging 和 Pasting
之前的hard voting 和soft voting集成学习,是看不同的算法来进行集成学习,而Bagging和Pasting集成学习则是看同一个算法对不同的样本进行学习得到不同的子模型,然后根据这些子模型进行集成学习。
集成学习的关键在于子模型之间的差异性,多样性越高,集成学习的效果越好。每个子模型只看样本数据的一部分
可以通过使用不同的算法、训练不同的数据子集或随机特征子集来增加子模型之间的差异性。

Bagging方法
Bagging(自助聚合)是一种常用的集成学习方法,通过放回取样训练多个子模型。
Bagging能够有效地利用有限的样本数据,通过训练多个子模型来提高整体模型的准确性。
Bagging可以通过并行处理加速训练过程,并能够天然地利用out-of-bag样本进行测试。
参数bootstrap=True就是有放回取样,也就是Bagging,否则就是Pasting
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
?BaggingClassifier
# 参数1是传入一个分类器
# n_estimators是创建多少个子模型
# max_samples 就是每个子模型要看几个样本数据
# bootstrap 是放回取样还是不放回取样
bagging_clf = BaggingClassifier(DecisionTreeClassifier(),n_estimators=500,max_samples=100,bootstrap=True)
bagging_clf.fit(X_train,y_train)
bagging_clf.score(X_test,y_test)13-4 oob(Out-of-Bag) 和关于Bagging的更多讨论
使用oob
Bagging的一个问题就是放回取样可能有一部分样本没有取到(平均大概37%样本取不到),而使用oob就是不需要使用train_test_split分成训练集和测试集了,直接使用总集,然后将没有取到的那些样本作为测试集。最后oob_score_ 参数就是score结果
bagging_clf = BaggingClassifier(DecisionTreeClassifier(),n_estimators=500,max_samples=100,bootstrap=True,oob_score=True)
bagging_clf.fit(X,y) #直接使用总集合
bagging_clf.oob_score_ #通过oob_score_ 得到score值使用n_jobs并行化处理
bagging集成学习可以很方便地进行并行化处理(多进程多线程等),使用n_jobs参数,-1代表使用所有的核心
bagging_clf = BaggingClassifier(DecisionTreeClassifier(),n_estimators=500,max_samples=100,bootstrap=True,oob_score=True,n_jobs=-1)
bagging_clf.fit(X,y)bagging的随机采样,除了之前的针对样本进行随机采样(默认),还可以针对特征进行随机采样(Random Subspaces),还可以即针对样本又针对特征进行随机采样(Random Patches)
在sklearn中,对特征进行随机采样,使用bootstrap_features=True设置对特征进行随机采样,max_features参数是设置采样的特征的特征数。
示例代码如下,max_features=1,bootstrap_features=True。如果是要使用即针对样本又针对特征进行随机采样,只需要把max_samples设置成和总样本数量不一样即可
#max_features是采样的特征的特征数,作用和max_samples类似的,max_samples是采样的样本的样本数
#bootstrap_features设置为True
random_subspaces_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,
max_samples=100,
bootstrap=True,
oob_score=True,
n_jobs=-1,
max_features=1,bootstrap_features=True)
random_subspaces_clf.fit(X,y)
random_subspaces_clf.oob_score_13-5 随机森林和Extra-Trees
随机森林:对于集成了成百上千的这种决策树模型的集成学习,有个更专门的名称,就叫做随机森林。sklearn中提供了一个专门的随机森林的类
from sklearn.ensemble import RandomForestClassifier
# n_estimators=500指有500个决策树
rf_clf = RandomForestClassifier(n_estimators=500,random_state=666,oob_score=True,n_jobs=-1)
rf_clf.fit(X,y)Extra-Trees(极其随机的森林)
也是一种随机森林,和普通随机森林相比,表现在决策树在节点划分上,使用随机的特征和随机的阈值。提供额外的随机性,抑制过拟合,但增大了bias(方差),拥有更快的训练速度
from sklearn.ensemble import ExtraTreesClassifier
#ExtraTreesClassifier默认bootstrap=False,需要改成True让他使用放回取样
et_clf = ExtraTreesClassifier(n_estimators=500,bootstrap=True,oob_score=True,random_state=666)
et_clf.fit(X,y)集成学习解决回归问题(调用方式和分类器基本一样)
from sklearn.ensemble import BaggingRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import ExtraTreesRegressor13-6 Ada Boosting 和 Gradient Boosting
另外一类集成学习的思路Bootsting,每个模型都在尝试增强(Bootsting)整体的效果
AdaBoost(Adaptive Boosting,自适应增强)是一种集成学习算法,通过组合多个弱分类器(如决策树桩)构建强分类器。其核心思想是迭代调整样本权重和分类器权重,使模型逐步关注难以分类的样本。以下是其关键要点:
核心思想
自适应调整:每一轮训练后,增加分错样本的权重,减少分对样本的权重,迫使后续分类器更关注错误样本。
加权投票:最终模型是所有弱分类器的加权组合,分类效果好的弱分类器拥有更高权重。
优缺点
优点:
简单高效,常与决策树桩结合使用。
自动处理样本重要性,减少偏差。
缺点:
对噪声数据和异常值敏感(可能过度调整权重)。
弱分类器不能太弱(错误率需低于50%)。
应用场景
二分类问题:如垃圾邮件检测、人脸识别。
基准模型:常作为对比其他算法的基线。
结合决策树:如AdaBoost + 决策树桩(如scikit-learn中的
AdaBoostClassifier)。
对比其他方法
VS Bagging(如随机森林):Bagging通过并行训练独立模型并投票,减少方差;AdaBoost串行训练,减少偏差。
VS Gradient Boosting:Gradient Boosting通过梯度下降优化损失函数,AdaBoost则通过样本权重调整。
总结:AdaBoost通过自适应调整样本权重和分类器权重,将弱分类器提升为强模型,是集成学习中提升(Boosting)的经典方法
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2),n_estimators=500)
ada_clf.fit(X_train,y_train)Gradient Boosting

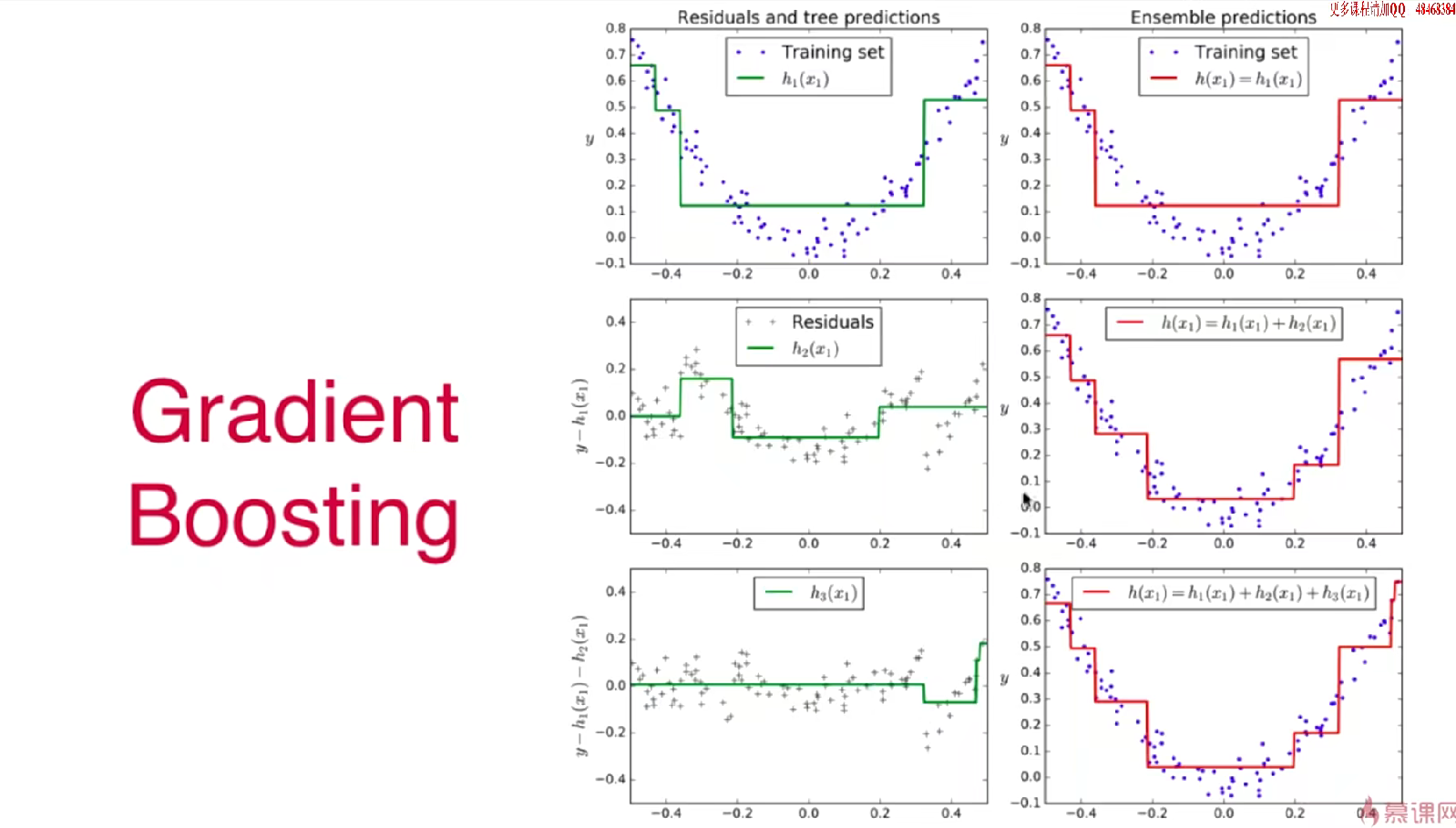
from sklearn.ensemble import GradientBoostingClassifier
gb_clf = GradientBoostingClassifier(max_depth=2,n_estimators=50)
gb_clf .fit(X_train,y_train)
gb_clf .score(X_test,y_test)Boosting 解决回归问题
from sklearn.ensemble import AdaBoostRegressor
from sklearn.ensemble import GradientBoostingRegressor13-7 Stacking
stacking是集成学习的另一种思路,也是集成学习,然后使用很多的模型进行预测,得到很多的结果(数值),然后不再像之前的集成学习那些直接使用这些结果进行运行得到最终预测结果,而是再基于这些数值来传入到另外一个模型来进行预测得到最终结果
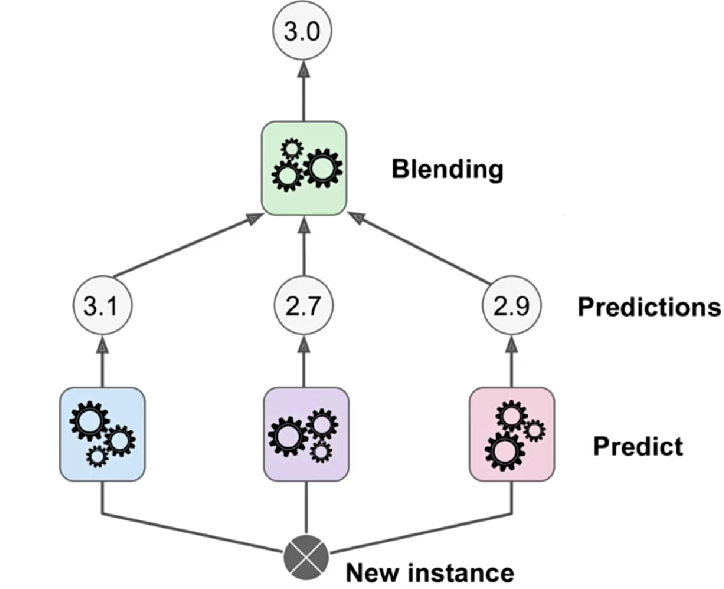
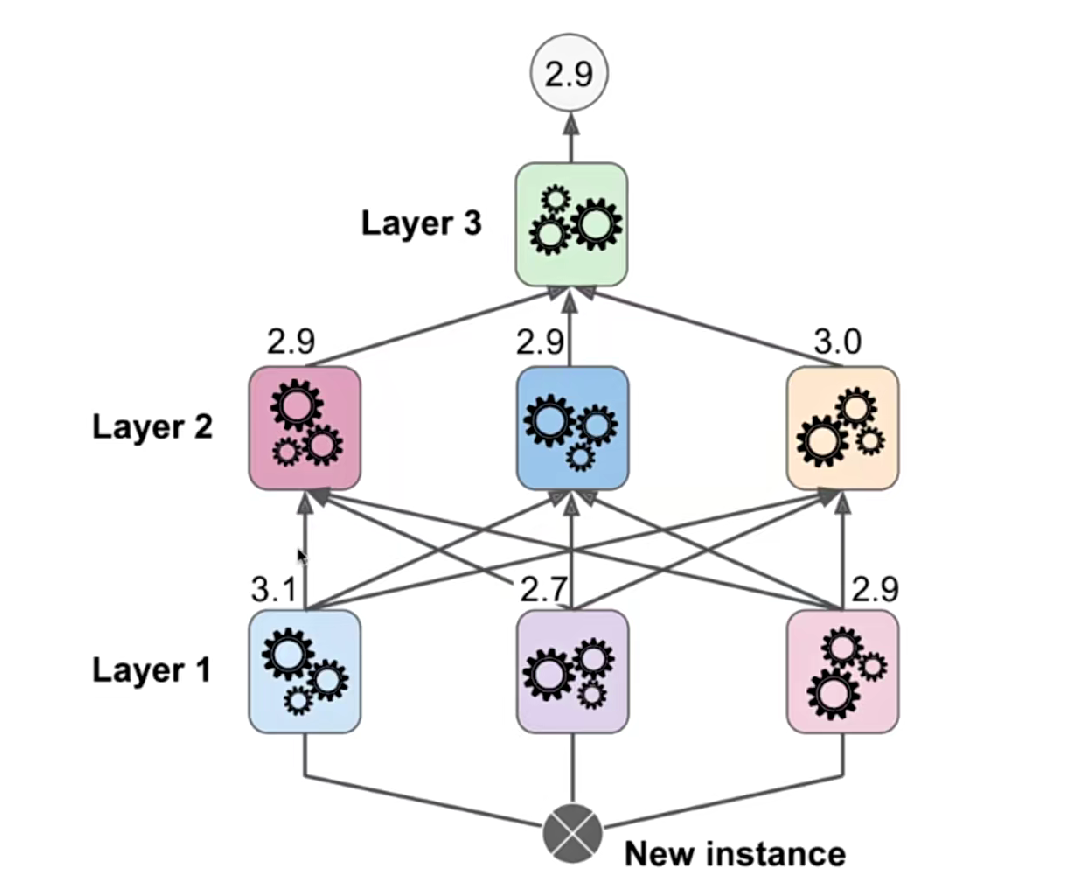
很像深度学习的神经网络。sklearn中没有提供任何借口来实现stacking的算法