

这是哔哩哔哩中小土堆的pyTorch快速入门教程的学习记录文档
线上课程链接:链接
课程
P6 Dataset类代码实战
Dataset是pytorch用来构建数据集的基类,至少需要我们重写__getitem__和__len__方法,__getitem__是用来可以使用索引来读取样本,__len__方法是用来告诉程序有多少个样本。其本质是类似列表,并且可以很方便地进行Dataset和Dataset间的数据集合并
from torch.utils.data import Dataset
from PIL import Image
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self,idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
root_dir = "../hymenoptera_data/train"
ants_label_dir = 'ants'
bees_label_dir = 'bees'
ants_dataset = MyData(root_dir,ants_label_dir) #蚂蚁数据集
bees_dataset = MyData(root_dir,bees_label_dir) #蜜蜂数据集
train_dataset = ants_dataset + bees_dataset #数据集合并,得到总的测试数据集。P7 TensorBoard的使用
首先需要安装tensorboard,`pip install tensorboard`
然后可以使用torch.utils.tensorboard.SummaryWriter,来绘制数据图片。(下面的logs是任意的一个文件夹名字,可自定义)
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
for x in range(100):
writer.add_scalar('y=x',x,x)
for x in range(100):
writer.add_scalar('y=2*x',2*x,x)
for x in range(100):
writer.add_scalar('y=3*x',3*x,x)
writer.close()绘制好数据图片后,如果要查看图片使用指令来打开tensorboard。下面的logs是对应的文件夹的名字。然后就可以打开一个地址,查看图片了
tensorboard --logdir=logs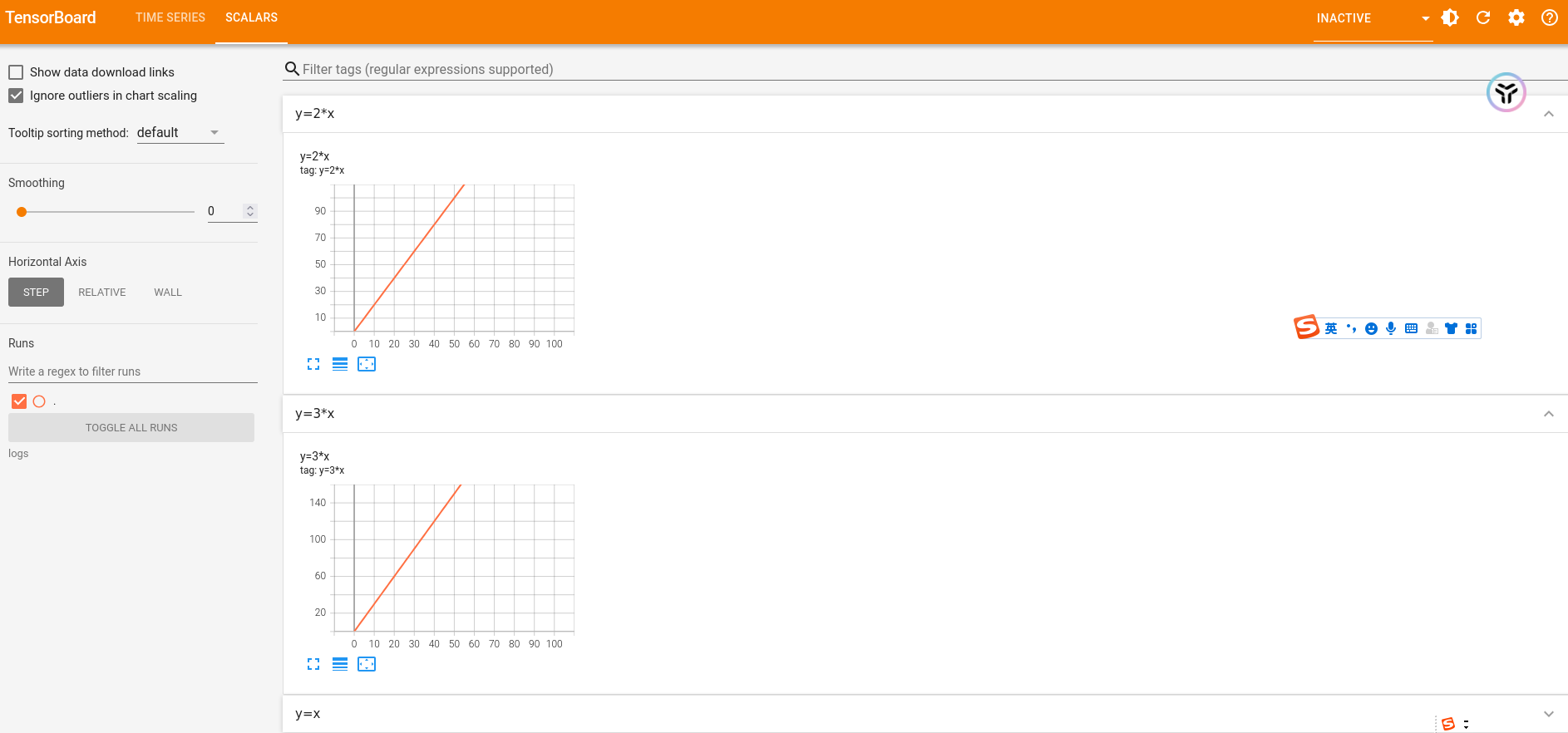
图片的读取
writer = SummaryWriter("logs")
#参数1是标题,参数2是图片数据(torsor或numpy类型),参数3是这个标题下的步骤标号。dataformats与图形的通道顺序有关
writer.add_image('image',img_array,1,dataformats='HWC')
writer.close()p3 Transform的使用
torchvision.transforms这个包/工具箱,存放了很多对图片的操作的类,比如转tensor或者图片变换、resize等等
pil_img = Image.open('../hymenoptera_data/train/ants/0013035.jpg')
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(pil_img)注意,transforms里面的工具,需要先创建工具对象,再使用工具,不能直接把参数传入工具(ToTensor)中。
常见的Transforms的工具的使用,需要关注输入,输出,以及作用,比如:
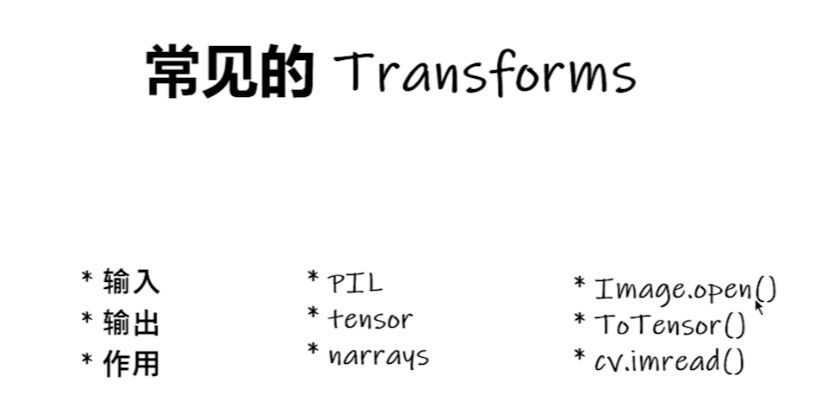
Compose是一个组合器,可以组合多个Transforms工具。
pil_img = Image.open('../hymenoptera_data/train/ants/0013035.jpg')
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(pil_img)
#Normalize
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(tensor_img)
writer = SummaryWriter('logs')
writer.add_image('tensor_img',img_norm,1)
writer.close()
print(pil_img)
#Resize -->使用工具后返回的是PIL类型
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(pil_img)
img_resize = tensor_trans(img_resize)
print(img_resize)
writer.add_image('tensor_img',img_resize,2)
writer.close()
# Compose
trans_resize2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize2,tensor_trans])
img_resize_2 = trans_compose(pil_img)
writer.add_image('tensor_img',img_resize_2,3)
writer.close()
#RandomCrop 随机裁剪
trans_random = transforms.RandomCrop(350)
trans_compose_2 = transforms.Compose([trans_random,tensor_trans])
for i in range(10):
img_crop = trans_compose_2(pil_img)
writer.add_image("RandomCrop",img_crop,i)
writer.close() tensor数据类型
为什么需要这个数据类型:tensor对象有很多和神经网络相关的一些函数,比如梯度、反向传播等
p10 torchvision的数据集的使用
pytorch框架的torchvision.datasets提供了很多常见的数据集
### **图像分类数据集**
1. **MNIST**
- **描述**: 手写数字灰度图像数据集,包含 0-9 共 10 类,6 万训练样本 + 1 万测试样本。
- **任务**: 经典入门级分类。
2. **Fashion-MNIST**
- **描述**: 替代 MNIST 的服装分类数据集,包含 T恤、鞋子等 10 类时尚单品,样本规模同 MNIST。
- **任务**: 分类(更复杂的图像但低分辨率)。
3. **KMNIST (Kuzushiji-MNIST)**
- **描述**: 日语平假名手写字符数据集,10 类,格式与 MNIST 兼容。
- **任务**: 跨文化字符分类。
4. **EMNIST**
- **描述**: 扩展 MNIST,包含数字、大小写字母共 47 类,样本量更大。
- **任务**: 多字符分类。
5. **CIFAR10 / CIFAR100**
- **描述**: 32x32 彩色自然图像数据集,CIFAR10 含 10 类(动物、交通工具等),CIFAR100 含 100 细类。
- **任务**: 小图像分类基准。
6. **STL10**
- **描述**: 96x96 彩色图像数据集,10 类(飞机、鸟类等),提供少量标注数据和大量未标注数据。
- **任务**: 半监督/无监督学习。
7. **ImageNet**
- **描述**: 大规模图像数据集(需手动下载),1000 类自然物体,常用于预训练模型。
- **任务**: 大规模分类/迁移学习。
8. **EuroSAT**
- **描述**: 卫星图像数据集,包含农田、森林等 10 类土地利用类型。
- **任务**: 遥感图像分类。
9. **DTD (Describable Textures Dataset)**
- **描述**: 纹理图像数据集,包含条纹、斑点等 47 种纹理类别。
- **任务**: 纹理分类。
10. **Places365**
- **描述**: 场景分类数据集,包含 365 类场景(如海滩、办公室)。
- **任务**: 场景理解。
---
### **目标检测与分割数据集**
1. **COCO (Common Objects in Context)**
- **描述**: 大规模复杂场景数据集,支持目标检测、实例分割、图像描述等任务。
- **任务**: 检测、分割、多任务学习。
2. **VOC (PASCAL VOC)**
- **描述**: 经典数据集(2007/2012 版),含 20 类物体,支持分类、检测、分割。
- **任务**: 多用途基准。
3. **Cityscapes**
- **描述**: 城市场景街景图像,精细标注的语义分割(如车辆、行人)。
- **任务**: 自动驾驶场景分割。
---
### **人脸与属性识别**
1. **CelebA**
- **描述**: 名人面部图像数据集,标注 40 种属性(如微笑、眼镜)。
- **任务**: 人脸属性分类/生成。
2. **FER2013**
- **描述**: 面部表情数据集,7 类情绪(愤怒、高兴等)。
- **任务**: 表情识别。
---
### **其他特殊任务**
1. **SVHN (Street View House Numbers)**
- **描述**: 谷歌街景门牌号图像,包含数字序列(如门牌号)。
- **任务**: 数字检测与识别。
2. **Omniglot**
- **描述**: 来自 50 种字母系统的 1623 类手写字符,每类仅 20 样本。
- **任务**: 小样本学习/元学习。
3. **LSUN**
- **描述**: 场景理解数据集,包含卧室、教堂等场景分类。
- **任务**: 场景生成与分类。
4. **PCAM (PatchCamelyon)**
- **描述**: 医学影像数据集,判断淋巴结切片是否含转移组织。
- **任务**: 二分类医学图像分析。
---
### **视频数据集**
1. **Kinetics-400/600/700**
- **描述**: 大规模视频动作识别数据集,包含数百类人类动作(如跳舞、打球)。
- **任务**: 视频动作分类。
2. **UCF101 / HMDB51**
- **描述**: 小规模视频数据集(101 类 / 51 类动作),如运动、乐器演奏。
- **任务**: 视频分类基准。
---
### **实用工具数据集**
- **FakeData**
- **描述**: 生成随机虚拟图像,用于测试和调试模型。
- **任务**: 代码验证。
---
### **注意事项**
- 部分数据集(如 ImageNet、COCO)需手动下载数据并指定路径。
- 视频数据集(如 Kinetics)可能需要额外依赖(如 `torchvision.io`)。
这些数据集覆盖了计算机视觉的主要任务,可根据需求选择合适的数据集进行实验或模型训练。import torchvision
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
#CIFAR10是一个图片分类的数据集;transform参数可以批量对图片进行处理,不需要可以不传入;#如果下载失败请关闭代理
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True) 如果datasets的数据集下载慢,可以在源码中找到链接,然后使用迅雷等进行下载,下载好之后放到对应的设置的root参数路径下即可。
DataLoader的使用
称为数据加载器,dataset是数据,数据如何取出、每次取多少样本、取样本是否随机等等问题是由DataLoader来决定。
torch.utils.data.DataLoader
使用的直接创建DataLoader对象,得到实例,这个实例是一个可迭代对象,可以直接进行遍历,遍历的每一项由datas和targets组成,一个datas由batch_size个样本组成。
PyTorch的DataLoader用于高效加载数据,支持批量处理、多进程加载等功能。以下是其主要参数的作用及常用配置:
dataset (必需):
指定要加载的数据集对象,必须继承自torch.utils.data.Dataset。例如自定义数据集或TensorDataset。
batch_size (int, 默认=1):
每个批次(batch)的样本数。训练时根据内存和模型需求调整(如32、64)。
shuffle (bool, 默认=False):
是否在每个epoch开始时打乱数据顺序。训练集通常设为True,验证/测试集设为False。
num_workers (int, 默认=0):
数据加载的并行进程数。设置为0时在主进程加载;>0时启用多进程加速(如设置为CPU核心数)。注意:Windows需在if __name__ == '__main__'中运行。
collate_fn (可调用对象, 默认=None):
自定义如何将多个样本组合成一个批次。用于处理变长序列(如填充)或复杂数据结构。默认自动拼接张量。
sampler (Sampler, 默认=None):
定义数据采样策略(如随机采样、顺序采样)。若指定,shuffle需设为False。常用如WeightedRandomSampler处理类别不平衡。
batch_sampler (Sampler, 默认=None):
直接生成每个批次的索引列表。若指定,则忽略batch_size、shuffle、sampler和drop_last。
pin_memory (bool, 默认=False):
为True时,将数据加载到锁页内存(pinned memory),加速GPU数据传输。建议在GPU训练时启用。
drop_last (bool, 默认=False):
若数据量不能被batch_size整除,是否丢弃最后一个不完整的批次。训练时可设为True以避免小批次影响。
timeout (float, 默认=0):
每个批次的数据加载超时时间(秒)。>0时,超时未完成会报错。多进程加载时可适当调整。
worker_init_fn (可调用对象, 默认=None):
初始化每个子进程的函数,常用于设置不同的随机种子(如数据增强)或配置进程环境。
prefetch_factor (int, 默认=2):
每个worker预加载的批次数量(PyTorch≥1.7)。增大可减少等待时间,但占用更多内存。
persistent_workers (bool, 默认=False):
是否在多次迭代后保持子进程存活(PyTorch≥1.7)。减少进程频繁创建销毁的开销tensorboard.SummaryWriter的add_images函数可以读取一组图片,比如DataLoader的每一项的imgs
test_set = torchvision.datasets.CIFAR10(root='./dataset',train=False,transform=transform,download=True)
test_loader = torch.utils.data.DataLoader(dataset=test_set,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
#使用tensorboard来显示每次batch的图片
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs')
for epoch in range(2):
for index,data in enumerate(test_loader):
imgs,targets = data
writer.add_images('test_set',imgs,index)
writer.close()
神经网络的基本骨架-nn.Module的使用(Neural network)
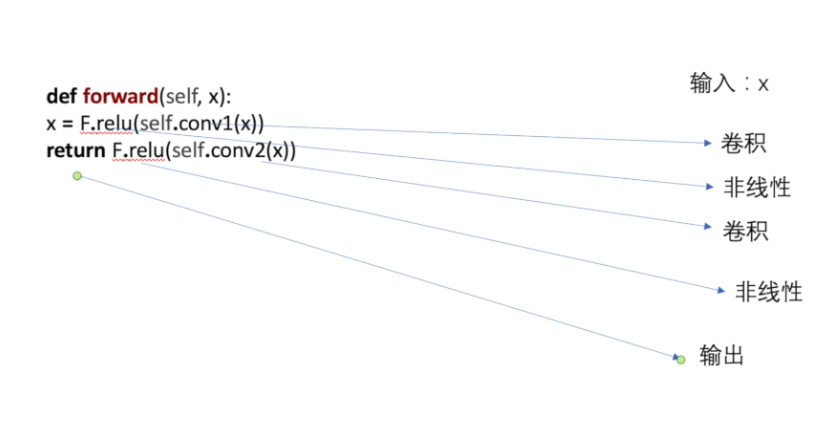
torch.nn对torch.nn.functional进行了封装,torch.nn.functional是更底层的一些函数,一般只需要学习torch.nn即可。
卷积(convolution)
torch.nn.Conv2d 二维卷积
参数:
以下是 `Conv2d` 各参数的简洁解释:
---
### 核心参数
1. `in_channels`
- 作用:输入数据的通道数(如 RGB 图像的 3)。
- 示例:输入形状为 (B, 3, H, W) 时,`in_channels=3`。
2. `out_channels`
- 作用:输出的通道数(即卷积核的数量)。
- 示例:`out_channels=16` 会生成 16 个不同的特征图。
3. `kernel_size`
- 作用:卷积核的尺寸(如 3 表示 3x3)。
- 影响:尺寸越大,感受野越大,计算量增加。
4. `stride`
- 作用:卷积核滑动的步长(默认 1)。
- 影响:步长越大,输出尺寸越小(如 stride=2 会减半输出尺寸)。
5. `padding`
- 作用:在输入四周填充的像素层数(默认 0)。
- 用途:保持输入输出尺寸一致(如 kernel_size=3 时 padding=1)。
6. `dilation`
- 作用:卷积核元素的间隔(默认 1)。
- 用途:扩大感受野(如 dilation=2 使 3x3 核等效于 5x5)。
7. `groups`
- 作用:输入与输出的分组数(默认 1,即不分租)。
- 用途:减少参数量(如 groups=2 时,输入和输出通道各分 2 组独立卷积)。
8. `bias`
- 作用:是否添加偏置项(默认 True)。
- 示例:`bias=False` 表示仅用权重,不加偏置。
---
### 其他参数
- `padding_mode`
- 作用:填充模式(默认 'zeros')。
- 选项:`'zeros'`(填充0)、`'reflect'`(镜像填充)、`'replicate'`(复制边缘值)。
---
### 关键公式
输出尺寸:

N:是batch_size,Cin是输入的channel通道数,Hin是输入的宽,Win是输入的高。类似的Cout是输出的channel通道数,Hout是输出的宽,Wout是输出的高。里面的公式是输出的宽和高的计算公式
### 使用场景示例
- 分类任务:常用 kernel_size=3, padding=1, stride=1 保持分辨率。
- 下采样:用 stride=2 或 kernel_size=2(如 MaxPooling 替代)这类任务直接使用最大池化的类。
- 轻量化模型:通过 groups=in_channels 实现深度可分离卷积(如 MobileNet)。
最大池化的使用
链接:https://pytorch.org/docs/stable/nn.html#pooling-layers
有很多池化的类,常用的有MaxPool2d
作用就是下采样
ceil_model参数的作用
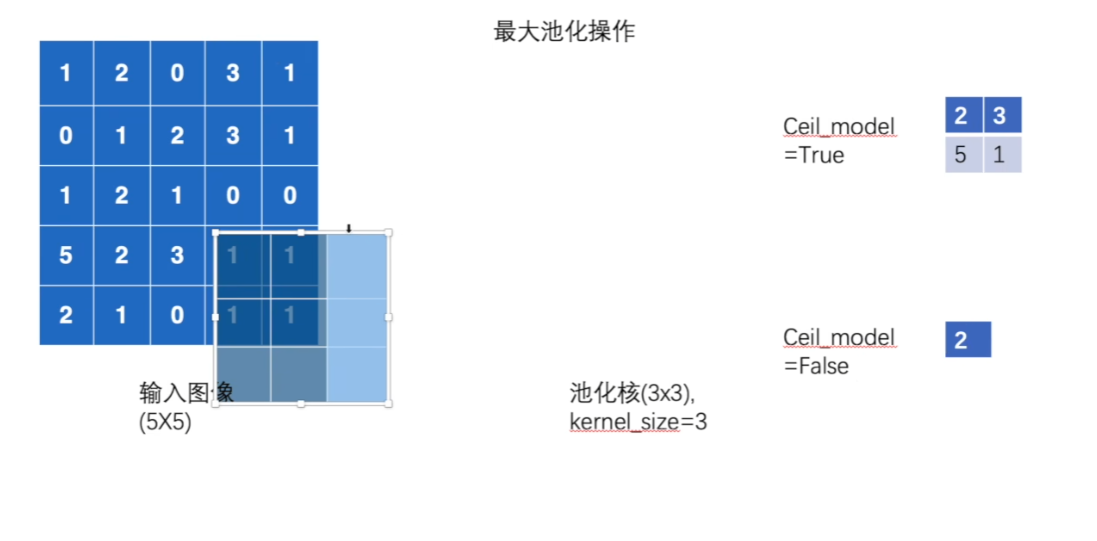
from torch.nn import MaxPool2d
class Tudui(torch.nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,x):
x = self.maxpool1(x)
return x
tudui = Tudui()
for data in dataloader:
imgs,targets = data
output = tudui(imgs)
print(output.shape)
break非线性激活(Non-linear Activations)
链接:https://pytorch.org/docs/stable/nn.html#non-linear-activations-weighted-sum-nonlinearity
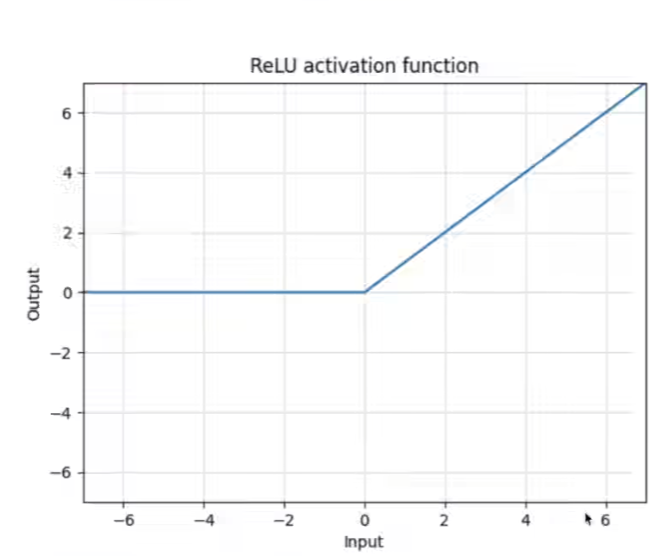
nn.ReLU
nn.Sigmoid
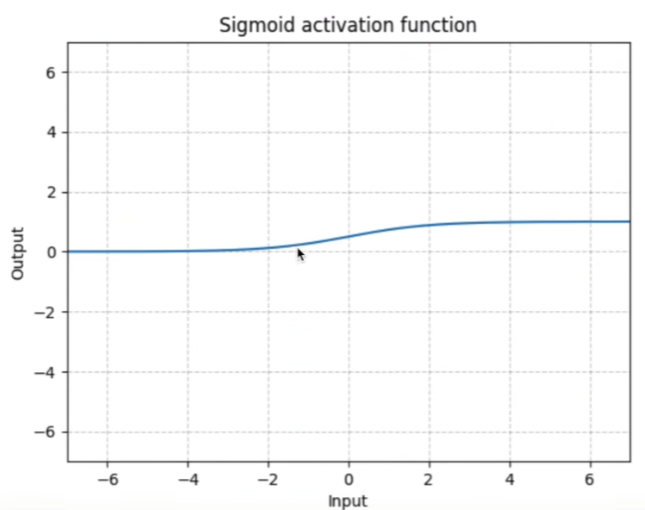
以nn.ReLU为例:
有一个inplace参数,是否直接修改传入的参数。如果是True就直接修改输入的x,如果是False就是不直接修改输入的x,而是返回新的值。默认是False
from torch.nn import MaxPool2d,ReLU
class Tudui(torch.nn.Module):
def __init__(self):
super().__init__()
self.relu1 = ReLU()
def forward(self,x):
x = self.relu1(x)
return x 线性层以及其他层
正则化层(Normalization Layers)
https://pytorch.org/docs/stable/nn.html#normalization-layers
nn.BatchNorm2d nn.BatchNorm3d
线性层
https://pytorch.org/docs/stable/nn.html#linear-layers
nn.Linear(in_features,out_features,bias=True),bias参数决定要不要加偏置(kx+b中的b)。
from torch.nn import Linear
class Tudui4(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear1 = Linear(196608,10)
def forward(self,x):
return self.linear1(x)
tudui4 = Tudui4()
for data in dataloader:
imgs,target = data
print(imgs.shape)
output = torch.flatten(imgs) #展平
print(output.shape)
output = tudui4(output)
print(output.shape)
print(output)
breakDropout 层(随机将一些元素变成0,防止过拟合)
torchvision下有一些预训练好的模型Models and pre-trained weights,可以使用:
https://pytorch.org/vision/stable/models.html
除了torchvision之外,torchaudio、torchtext都有对应的预训练好的模型,直接直接使用,不需要自己写网络结构。
Sequential(序列)的使用
https://pytorch.org/docs/stable/generated/torch.nn.Sequential.html#torch.nn.Sequential
就是不需要每个层都创建一个变量,直接使用Sequential传入一个层序列即可。更简洁。见下一章节
神经网络小实战
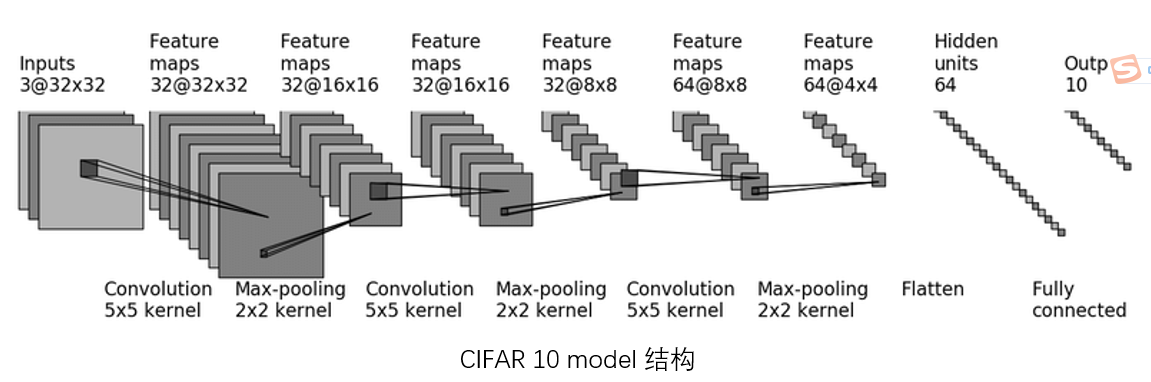
方式1:
class Tudui(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(3,32,kernel_size=5,padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32,32,kernel_size=5,padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32,64,kernel_size=5,padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten1 = Flatten()
self.linear1 = Linear(1024,64)
self.linear2 = Linear(64,10)
def forward(self,x):
x = self.maxpool1(self.conv1(x))
x = self.maxpool2(self.conv2(x))
x = self.maxpool3(self.conv3(x))
x = self.flatten1(x)
x = self.linear1(x)
x = self.linear2(x)
return x方式2:(使用Sequential,等价的)
#Sequential的使用,就是不需要每个层都创建一个变量,直接使用Sequential传入一个层序列即可。更简洁
class Tudui2(torch.nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32,64,kernel_size=5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x):
x = self.model1(x)
return x一般写完神经网络,需要简单验证一些网络是否正确,是否正确是指各个网络的输入输出是否匹配)
tudui = Tudui2()
input_ = torch.ones((64,3,32,32))
output_ = tudui(input_)
print(output_.shape)损失函数以及反向传播
损失函数:https://pytorch.org/docs/stable/nn.html#loss-functions
!使用的时候要注意input、target、输出的维度是怎么样子的
L1Loss 平均误差
MSELoss 平方差
loss_mse = nn.MSELoss()
result_mse = loss_mse(input,target)CrossEntropyLoss 交叉熵
nn.CrossEntropyLoss()
for data in dataloader:
imgs,targets = data
outputs = tudui(imgs)
result_loss = loss(outputs,targets)
result_loss.backward() #进行梯度计算,反向传播优化器torch.optim
https://pytorch.org/docs/stable/optim.html
有很多的优化器,常见的就是梯度下级法SGD
optim = torch.optim.SGD(tudui.parameters(),lr=0.01) #梯度下降发
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs,targets = data
outputs = tudui(imgs)
#print(outputs,targets)
result_loss = loss(outputs,targets)
#print(result_loss)
optim.zero_grad() #清空之前的梯度,一定要
result_loss.backward() #进行梯度计算,反向传播
optim.step() #优化器进行调优
running_loss = running_loss + result_loss ##把每一轮的loss加起来
print(running_loss)现有网络模型的使用以及修改
视觉相关的模型:https://pytorch.org/vision/stable/models.html
以VGG分类模型为例。
https://pytorch.org/vision/stable/models/vgg.html
pretrained参数(改名为weights了):True代表使用预训练好的参数,False代码不使用
progress参数:True显示下载进度条,False不显示
在原模型基础内,创建一个子模型,并定义子模型的层
vgg16_true = torchvision.models.vgg16(weights=True)
vgg16_true.add_module('add_linear',nn.Linear(1000,10))如果想在原有的子模型(classifier子模型)里面添加新的层的话,就这样
vgg16_true.classifier.add_module('add_linear',nn.Linear(1000,10))如果想要替换原有的某个层
vgg16_true.classifier[6] = nn.Linear(4096,10)模型的保存和修改
第一种:直接保存,直接加载。(模型结构+模型参数)
torch.save(vgg16,'vgg16_method1.pth')
#加载
model = torch.load('vgg16_method1.pth',weights_only=False)第二种:只保存权重参数,加载前需要先创建模型再导入参数(官方推荐)
torch.save(vgg16.state_dict(),'vgg16_method2.pth')
#加载
vgg16_2 = torchvision.models.vgg16(pretrained=False)
vgg16_2.load_state_dict(torch.load('vgg16_method2.pth')) #加载状态字典(权重参数)